
Could Quoting Data Patterns Help in Identifying Journalistic Behavior Online?
By Subramaniam Vincent, Xuyang Wu, Maxwell Huang, and Yi Fang
[Citation: S. Vincent, X. Wu, M. Huang, and Y. Fang (2023). Could Quoting Data Patterns Help in Identifying Journalistic Behavior Online? #ISOJ Journal, 13(1), 33-64]One of the hardest problems for recommenders and aggregators when sorting news and news-like content is to identify whether a news site is in fact a “journalistic actor” or is acting as a journalist does or “should.” The problem of journalistic boundaries online — what counts as journalism and what does not – is a hard one for news ranking and distribution. Journalism’s contested ethics complicate the algorithmic approach further. Quoting, one of the most rudimentary routines in everyday journalism, is a key marker of journalistic behavior. Our question is: Could analyzing quotes for source diversity proportions in “news” sites show us any identifiable boundaries between different types of news sites such as local, national, hyper-partisan, disinformation sites and others? Our hypothesis is that quoting related data may be useful. We examined quotes data extracted from several thousand English news sites and found that the case for classification boundaries does exist.
One of the hardest problems for digital news aggregators and social media products when sorting news and news-like content is to identify whether a publisher or author is, in fact, a journalistic actor or is acting as a journalist does or “should.” Both news and the boundaries of journalism (Carlson & Lewis, 2015) are not well-defined and continually contested in democracy. While some debates are long-running, the internet, search and social media have brought a new turbulence to the discussions about what is journalism and what is not. The problem of journalistic boundaries and contested journalistic ethics complicates the algorithmic approach to news ranking and distribution.
Quoting, one of the most rudimentary routines in everyday journalism, is a marker of journalistic behavior. Could analyzing quote data such as source diversity proportions for “news” sites show us any identifiable boundaries in such behavior? Would local news sites differ from their national counterparts? How would hyper-partisan sites and opinion sites line up? Would disinformation sites show different gender and expert quote proportions than traditional news sites? Site “behavior” is a key pillar of actor classification on the big tech platforms, and in particular, they use the term “inauthentic behavior” to identify bad actors.
Our hypothesis is that quote data proportions from “news-like” websites, if examined for proportionality patterns, will likely have useful signals around the sites’ approaches to journalism. This may open the door for deep examination of journo-technical questions such as: Could we build a signals-paradigm for authentic journalistic behavior? In our analysis, we asked whether quoting proportions around gender, expertise, community quotes and other criteria might serve as a proxy for authentic journalistic behavior, and if so how. We created a research dataset to explore these questions both by human observation and automated data analysis and reviewed our hypothesis.
Literature Review
Qualitatively, many systematic questions within journalism’s contested boundaries are dealt with comprehensively in the book Boundaries of Journalism (Carlson & Lewis, 2015). This effort examines journalism’s boundaries around professional norms, practices and participation, broadly situating it as an ever-evolving cultural occupation. Our interest is in computational approaches to identifying journalistic boundaries online. One computational approach evident in the literature here has mapped the question of identifying journalism and/or boundary-behavior to identifying journalists, using easily available social media speech and behavior to identify who may or may not be a journalist relative to a non-journalist. One such approach (De Choudhury et al., 2012; Zeng et al., 2019) involves taking advantage of claims, assertions, keywords and associations journalists make on Twitter into a category classification problem for machine learning. An earlier approach (Bagdouri & Oard, 2015) used “seed” sets of pre-identified journalists combined with journalism keywords for down the line identification.
Our interest, though, is at the site-level or publication-level. One notable computational effort that attempts to evaluate a site-level approach uses publicly available third-party media bias and factuality ratings data to build predictions on news site factuality and political leaning (Baly et al., 2018). Indeed, we use labels in this effort’s dataset in our work. Independent of academic efforts, big tech news distribution platforms already use data about and from news sites for ranking or prioritization on news feeds. This indicates the use of site-level signals (computed or otherwise) in news recommenders (Smyrnaios, 2015). There has been a lacuna in the area of site-level analysis using computation methods that explicitly create datasets around specific and well-understood vocabularies that describe journalistic work systematically, which in turn may manifest in news text and go untapped at scale for boundary detection or journalism-presence signals. This is where we situate our work around the use of quoting and source-diversity data about quotes.
The Problem of Boundaries and Boundary Detection in Journalism
As we noted in the introduction, one of the hardest problems for platforms when sorting news and news-like content is to identify whether another publisher or author is, in fact, a journalistic actor or is acting as a journalist does or should. Implicit in this problem are the definitions. Who is a journalist? What is news? Is news strictly called so when professional journalists produce it? Anyone can claim to be a “journalist,” whether or not their work is seen as news, or breaking news. Likewise, is everything newsworthy that a newsmaker says or does, automatically “news”?
Furthermore, there is a bidirectional flow of meaning and conflation between the words “news” and “journalism” that creeps over into the boundarylessness of both fields. In addition to this, journalism, through the work of journalists, has a power relationship with other actors in a democracy — policy makers, politicians, bureaucrats, criminals, scamsters, disinformation super-spreaders and so forth — and hence a relationship with democracy itself. The relationships manifest through sourcing as quotes in the news. Data about quotes, their frequency (proportionality) and perhaps other characteristics of quotes such as proportion of expert vs. non-expert quotes, gender, length of quotes, etc., may carry the deeper or structural behaviors implicated in these sourcing relationships.
For the technology platforms, classifying online news content is complex because the boundaries of journalism (Carlson & Lewis, 2015) are not well-defined and continually contested in democracy. Disinformation actors want to take advantage of the internet’s flattening of the space between journalism-produced “news” and “content,” a manifestation of boundary breaking, to sow confusion, anxiety, cynicism and propel false narratives (Vincent, 2020; Vincent, 2023). It is into this quagmire that we launched our study.
In particular, the problem of boundaries has complicated and influenced the algorithmic approach to news quality scoring and distribution. Third-party technology entities distributing news worry about technical definitions of journalism causing new negative externalities such as excluding smaller less industrialized truth-oriented news actors. They prefer to operate with definitions of “news” (News Distribution Ethics Recommendations, 2022) that differ platform to platform. Our question is where do we start if we are to explore reliable signals about journalistic behavior to complement or supplement existing site-level signals in algorithmically curated news feeds?
From a data standpoint, approaching such questions requires pinning down and defining behaviors that are journalistic — for example, adherence to facts, reality, accuracy, multiple perspectives and quoting people. In this study we look at one journalistic behavior: quoting. We test a hypothesis that estimating source-diversity proportions (using some journalism ethics vocabulary) for quotes in news articles from a given site, at scale, could be a helpful marker for identifying and delineating different types of journalistic boundaries. This could be the basis for building a suite of tools — dataset creation about news and ethics as well signals to stack on to and clear the noise in existing machine-led classification mechanisms.
Journalism Ethics Data and Boundary Detection
Journalism ethics concerns itself with the right and wrong of journalistic work and decisions, usually undertaken by writers, reporters, photographers, editors, columnists, producers, publishers and so forth. In the United States, many news organizations and journalists acknowledge allegiance to a code of ethics built around seeking the truth, minimizing harm, acting independently and being accountable and transparent (SPJ Code of Ethics–Society of Professional Journalists, 2014). More recently, however, a debate on new journalistic norms has emerged where there is a shift to questions of diversity and inclusion (or lack of it), bias, amplification, false equivalence and more (Columbia Journalism School, n.d.).
When journalists and news organizations strive to consistently apply ethical considerations to their work, evidence of this application is likely to manifest in their work online. Applying this to quoting, our question is whether such behavior should be identified using computational and hybrid approaches? If so, are they markers for journalism itself? There are implications for journalism’s boundaries here because of the possibility that ethical routines (such as a greater balance in gender for quoting experts, or a higher proportion of quotes of people without formal titles to represent community views) are usually deeper in the reporting practice, and their manifestations may be harder to game by inauthentic journalistic and/or news actors. The intuition is that an absence of specific journalism ethics routines in non-journalistic actors producing news-like content may be discernible through its corresponding lack of manifestation. Or, the degree and pattern of manifestation of this behavior may be different enough when compared with journalistic organizations, that it is detectable.
Quoting as a Facet of Journalistic Behavior
Quoting people is both a manifest and deeply cultural activity in journalistic work. It is almost second nature to reporters and opinion journalists to quote people. Quoting serves a variety of different purposes in news stories:
- It adds credibility to the reporter’s story; the reporter was “on the scene” and/or talked to people involved; the reporter talked with a number of people and decided to relay their views, responses, reaction, justifications, lived experiences and perspectives about the question or issue through quotes,
- It allows the reporter to show what questions s/he asked of the person and for which the quotes are responses,
- Direct quotes let the authentic voice of the quoted people to come out,
- Reporters can relay the views of people they are sourcing from to each other, and get reactions and quote those too (this is the “I disagree/agree with so and so” type of quoting),
- Adds a conversational and accessible style to everyday stories,
- Allows readers to relate to the people quoted more directly,
- Allows the reporter to relay powerful, persuasive, rhetorical or affective statements as quotes for readers to engage with the story. Often such quotes can drive the frame of the story or even the narrative (and this power in journalism is abused to amplify false claims too), which the reporter allows implicitly or explicitly.
- Reporters can quote people at length or quote them in brief depending on many factors, including but not limited to story frame, narrative fit or direction of the inquiry.
These ends have also changed and evolved with the arrival of social media. Because newsmakers (politicians, policy makers, scientists, celebrities, artists, sports stars and others) are already directly on social media, their own direct reliance on reporters to relay their views to the public is diminished. But the questions reporters generate are unique to the story inquiry, and hence when those responses are quoted in stories, their value exists independent of whether or not the sources directly said those words on social media.
The Opportunity for Boundary Detection
The central opportunity for boundary analysis and detection comes from the intuition that habits (journalistic or otherwise) do not change very easily. This is rooted in two reasons, at the very least.
One, it is costly to contact people. Reaching people after several attempts of not being able to, getting responses, developing relationships, avoiding being manipulated, etc., is real effort and necessarily time consuming. Once journalists develop relationships with a range of people, especially with some structural power (title in government or associations/organizations), the tendency to stay in contact and quote the same people over and over again for new inquiries and controversies, is real and productive. Two, journalists are themselves trapped in their own social networks and tend to know more people from their social/ethnic group or gender or professional class, or prior occupational background. (For example, if they came into reporting after a law career, they are likely to know more lawyers, which helps with sourcing for legal stories.) We expect these habits — even with some expected swing or cadence around news cycles, political seasons, and major events — will simply show in the quote proportions data.
Fundamentally, quoting decisions involve considerations that have ethical dimensions. A quantitative aspect of this is the “How often”? question:
How often are men quoted?
How often are women quoted?
How often are people who identify as non-binary quoted?
How often are experts or people with formal titles quoted?
How often are community members (people without titles) or witnesses, bystanders, people with lived experiences, and people with knowledge of local history quoted ?
How often are people of minority, or historically or recently marginalized, communities quoted?
How often are rural people quoted? And urban?
These become questions around which news sites and reporters can see their own patterns, and the DEI (Diversity, Equity and Inclusion) movement in journalism is currently driving discourse and reform in reporters’ sourcing practice for greater inclusion and accuracy in storytelling. (It must be said here that the “how often” is not the only type of useful empirical question involving quotes. What people are quoted about also matters.)
Method
For the purposes of our inquiry, we appropriate our lens on quoting to curate data and datasets at the news site level, about quotes. A news site’s output is in essence, the output of a group of news and commentary writers operating as a team, with gatekeeping usually done by editors. In this study, we only account for text-based stories from conventional text-based websites that may also carry video and audio. We did not include pure-play video or audio news outlets. (See section on limitations.)
Depending on the nature of the site, there could be reporters, freelancers, columnists or invited opinion writers in the writing group, or plain commentary sites simply have everyone as an opinion contributor. We compute proportions of source-diversity in quotes across gender and title (and cross-categories such proportion of quotes of women with and without title) for large numbers of articles from these sites, and these represent the initial “ethics features” of our dataset about sites. Before we proceed with the main analysis on our hypothesis that journalistic boundaries may exist in the data, we need to assess a fundamental question:
Are the source-diversity proportions and quote properties computed at scale for individual news sites systematic, i.e. are such measures reliable? Or do these site-level values for each site fluctuate so much across short differences time periods that using them to compare between sites itself is moot? (We used a well-known statistical method to determine reliable measures and verified this for our dataset. See later section on systematicity of proportions data.)
We then did a manual exploratory data analysis on the ethics features to throw light on a number of questions:
Do known (i.e. labeled) disinformation sites show up differently for computed value ranges of the features?
Do the proportion values for the ethics features help explain intuitions about particular types of journalism such as opinion journalism, trade/finance/technical sites, women’s websites and so forth?
How do traditional journalistic sites, i.e. the mainstream U.S. press, compare between national and local? What types of sites offer high proportions of community quotes vs. experts? How do newer-age digital news organizations compare?
How We Created the Dataset
We created a dataset for over 5,000 U.S. “news” sites. Starting with the U.S. news sources in the NewsQ database’s sites list (News Quality Initiative, 2020), we identified a corpora of legally usable news article archives. We used three corpora sources:
- Webhose.io’s COVID-2020 (Dec 2019-Feb 2020) corpus (Webz.io., 2020)
- A Lexis Nexis 3TB news archive corpus of three months March-April-May 2020.
- The Fake News Corpus on Github (2016+) (Szpakowski, 2016)
Processing Pipeline to Deliver Quotes Data
We built a processing pipeline (see Figure 1) using Stanford University’s CoreNLP package (Manning et al., 2014) for natural language processing (quotes and titles extraction), insertions into a database, and computations to derive the source-diversity proportions using Santa Clara University’s high performance computing cluster (WAVE Research Projects, n.d.). We extracted all the data around quotes from the stories and inserted them into a relational database with a schema designed around sources, articles, URLs, quotes, people, titles, organizations and some custom data for project buckets to hold various experimental runs together.
- Ground-truthing: We tested the Stanford CoreNLP system with ground truth data (manually reviewed quotes, speakers, titles, organizations, gender, etc.) for a 20-article proto corpus of traditional sources and 30-article proto-corpus of fake news sources.
- Accuracy of annotations: We documented the following accuracy scores for different aspects of our annotation system. Our interest in accuracy relates to boundary detection. We can tolerate a level of inaccuracy that is high enough that systematic differences in ethics data proportions are still a reliable indicator of behavioral differences in quoting.
- Speaker resolution for mainline news sources: 92% accuracy.
- Speaker resolution for “fake news” sources: 86% accuracy.
- Title presence resolution for mainline news sources (is the quoted person identified with a title, even if the exact title is not matched): ~86%.
- Title presence resolution for “fake news” sources: 67%.
- Gender detection system: We used a hybrid tandem system of using Stanford CoreNLP first (pronoun presence, he/she), gender_guesser (open source) next, and a commercial API service called Gender_API at the final level if the first two do not resolve.
- Published accuracy for Gender_API is 92% for European name corpora. Our tandem system during ground truth testing was able to get 87% accuracy for gender.
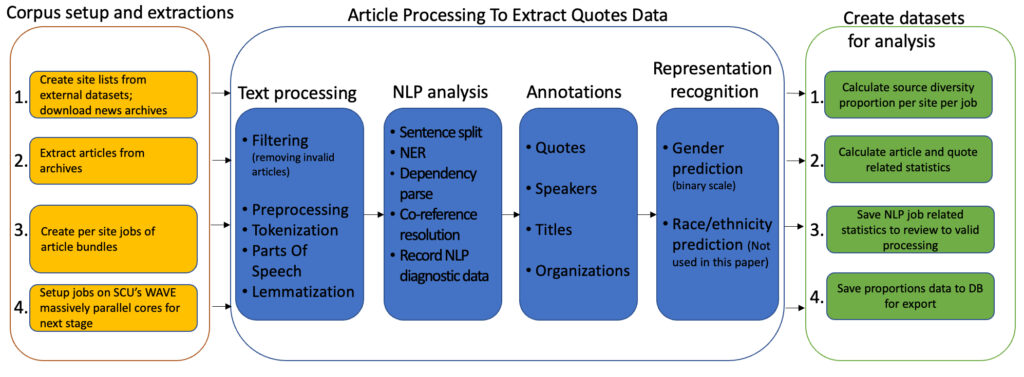
Figure 1: Flow diagram showing creation of quote proportions datasets from news archives. (Shang et al., 2022)
List of Per-Site Properties for the Dataset
Our final list of 29 source-diversity, quotes and article related properties created at the news-site level for our dataset is in Appendix B. For purposes of length, in this section, we describe only those properties we use in this paper’s analysis, while maintaining the same property serial number as in the appendix.
For the property definitions below, valid quotes are quotes of length > = five words. Short or dropped quotes are quotes of length less than five words (property #29).
- article_len_distr: Mean, media and standard-deviation of article-word-lengths in article sample.
- prop_quotes_with_title: the number of quotes where speaker has title/the number of total valid quotes with speaker.
(The title related properties starting at 12, and going down, are in a category called Known vs. Unknown in journalism ethics [Gans, 2004]).
- prop_quotes_without_title: the number of quotes where speaker has NO title/the number of total valid quotes with speaker.
- prop_speakers_with_title: the number of unique speakers with title/the total number of unique speakers.
- prop_speakers_without_title: the number of unique speakers without NO title/the total number of unique speakers.
- prop_quotes_gender_female: the number of quotes which gender is female/the number of total valid quotes with speaker.
- prop_quotes_gender_male: the number of quotes which gender is male/the number of total valid quotes with speaker.
- prop_quotes_known_gender_female: the number of quotes which has title and gender is female/the number of total valid quotes with speaker and with title.
- prop_quotes_known_gender_male: the number of quotes which has title and gender is male/the number of total valid quotes with speaker and with title.
- prop_quotes_community_gender_female: the number of quotes with NO title and gender is female/the number of total valid quotes with speaker and without title.
- prop_quotes_community_gender_male: the number of quotes with NO title and gender is male/the number of total valid quotes with speaker and without title
- prop_quotes_dropped_too_short: the number of quotes less than five words in length/(the number of total valid quotes + total quotes less than five words in length).
In our proto experiments, we observed from ground truth data that Stanford CoreNLP quote-to-speaker resolution has higher accuracy for quotes of length five words or more. We also found that short quotes are not spoken ones. They are slogans, catchy phrases, etc.: “Housing first,” “Build Back Better,” “Make America Great Again,” etc. So we use quotes > = five words for all source-diversity proportions calculations. Since our interest is in journalistic quoting of people as a systematic behavior, we also know that when journalists invest time in interviewing or source from people there will usually be at least one other quote in the same article that is longer, even if there is a short quote from that person. So our claim is that we do not run as much of a risk of under-counting legitimately quoted people by dropping the short quotes from source-diversity analysis. Instead, we created a separate, complementary property: proportions of quotes that are below five words in length. We initially marked this property as experimental. But we did see large differences in the ranges for this value between different types of news sources, so we included it in our analysis. (More methodology details in Appendix A and B.)
Analysis
Systematicity in Quoting Behavior: An Introduction
Our central thrust is that if journalistic quoting practices are substantially different in different types of sites, this may show as boundaries in source-diversity proportions that separate those different types of news sites. However, for this, source-diversity proportions themselves have to be systematic to a site’s news stream, as noted earlier, i.e. they do not change dramatically, or they do not change to the degree that they make the idea of boundaries itself moot. So we wanted to find a way to test the systematicity of source diversity proportions in quotes. As noted earlier, our intuition here is that journalistic routines are often habits (such as the list of experts a reporter goes to, or when a reporter may go to some types of sources and when not) and that these routinized practices tend to repeat themselves over and over again on story cycles or story series cycles. One solution: process a very large sample of stories from the site that was analyzed (such as six months or one year’s worth of data), and calculate the long-term mean for each of the source-diversity proportions.
However, this leads to a new problem. We may not always have access to the full long-term archives of a news source, and even if we did, calculating that for thousands of news sources on demand to develop a systematic source-diversity proportion set appears to not be very cost-effective computationally. Also, what if a new online news source is relatively low in volume and the detection system does not have enough time to wait for several months to gather 5,000 or 10,000 article samples? We addressed this problem using a statistical technique called bootstrap sampling (Dror et al., 2018)
Establishing Systematicity in Proportions
We wanted to answer one question: What smallest sample of size of randomly selected articles from a news source may reasonably represent the proportions data? At what sample size would there be no more than a tolerable variance (say 5% or 10%) with respect to the long-term mean for a given proportion property? The long-term value is usually calculated from say 5000, or 10,000, or 20,000 articles of that site.
The bootstrap method is a statistical technique for estimating quantitative values about a population by averaging estimates from multiple small data samples, re-sampled from the same pool. (Re-sampling involves replacing the earlier retrieved sample back into the pool, i.e. it is not removed. In normal random sampling, the earlier picked sample is removed from the pool.) First, we choose the number of times we will draw the bootstrap samples (news articles) from the pool (for example 20 times). And we also pre-define the sample size of the article for each source, i.e. the number of articles. For each bootstrap sample, we randomly select articles of the chosen sample size (e.g. 500). Then we calculate the source-diversity and quote related statistics for that sample set, and repeat for each set. Finally, we calculate the mean and standard deviation for our source-diversity proportions across all the sample sets. In addition, we calculate the 95% confidence interval based on the statistical results.
To calculate a confidence interval (two-sided, upper bound and lower bound), we follow these steps:
- Assume the sample size as 500 for each bootstrap sample sub-dataset.
- Find the mean value of your sample.
- Determine the standard deviation of the sample.
- Choose the confidence level. The most common confidence level is 95%.
- In the statistical table find the Z (0.95)-score, it’s 1.959.
- Compute the standard error and multiply this value by the z-score to obtain the margin of error.
- Subtract the margin of error from the mean value to obtain the confidence interval. lower bound = mean – margin of error; upper bound = mean + margin of error.
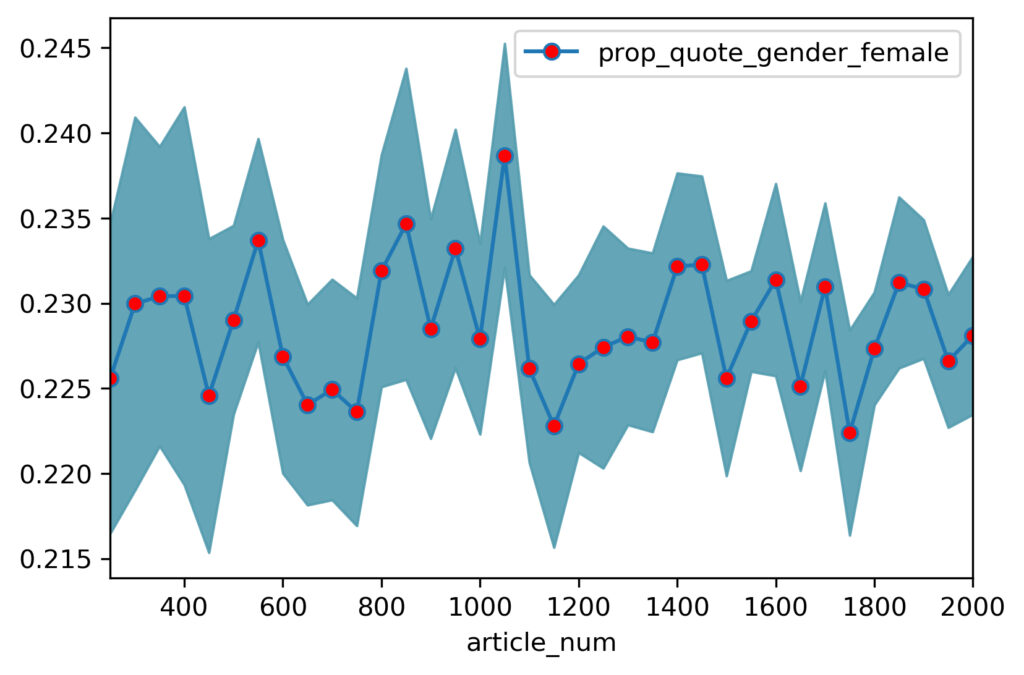
Figure 2: Example of bootstrap sampling to decide acceptable sample sizes to estimate source diversity proportions. This chart shows the proportion of quotes for women for a news site in the 23% range. The variance from the mean (amplified at this scale) is higher at very small sample sizes (expected) and reduces as larger samples are used to calculate the statistics.
For eight sources (six mainline news — journalistic sites — and two well-known disinformation sites), we annotated between 5,000 to 20,000 articles) and established the long-term means for the source diversity and other quoting proportion values. The sites were: CBS SF Bay Area, Modesto Bee, Vice, Washington Examiner, Fox News, Breitbart News, 21CenturyWire.com and TheLibertyBeacon.com. The last two in the list are well-known disinformation sites. The first six are news sites on the political left and right. We found that at 1,000 samples onwards the proportions stabilized for the sources we tested. At 500 samples, the departure from the long-term mean reduced to 10% or so.
The final dataset we used for the analysis in this paper has 5,171 sites of which 2,617 sites have a 500-sample bootstrap determined source-diversity and quote data proportion values. The rest have smaller article numbers in the samples used for the proportions calculation because those sites were already very low in volume.
Manual Review Findings in our Dataset
Given the accuracy limitations of the annotations and gender detection systems, we first wanted to manually review the full dataset using routine spreadsheet sorting and clustering techniques to see what sites emerge at the edges of the proportions (highest and lowest ranges of values). Understanding which sites fall at the edges would allow us to identify those sites quickly and verify what types of sites these were. And to the degree their sourcing pattern was expected on those sites, it would also validate our system and dataset as reasonably accurate in representing the quoting practice for the purposes of rough review.
We sorted the sites around various source-diversity proportions such as gender (male/female), titled/non-titled, short quote proportions, average number quotes per article, etc. It was relatively easy to see types of sites clustering around the two major ethics features in the data: gender and title proportions. One surprising element was the emergence of the proportion of short quotes as a distinctive feature for different types of sites. We will go more into this further.
- Gender proportions of quoted people.
- Titles (expert/official) vs. non-titles (community) proportions.
- Short quotes (< five words).
We also used Tableau to do multi-variable cluster analysis for 2,600 sources having 500 sample articles in the dataset. (See Figure 9.)
1. Gender proportions in quotes:
Many news sites and magazines targeting female audiences rank very high on gender proportions for both expert and community quotes. These include Vogue, Marie Claire, O, The Oprah Magazine and Refinery29. We see this mostly as validating the data annotation system we are using. Atlantablackstar.com, a progressive narrative news site target, was an example of a digital community news site, off the mainstream media, that has among the highest proportions for women being quoted. It is not a gender-focused news site. This site stood out as an example of diverse sourcing in evidence, systematically.
Conservative-leaning disinformation sites (e.g. 21CenturyWire.com) are showing an 80%–20% proportion split between male and female quotes, where mainline news sites almost all fall in the 50%–50% to 70%–30%. Partisan “left” opinion sites also show around 60%–40%, male-female proportions split, indicating that merely being “left-leaning” has not altogether balanced out the gender quoting proportions.
Opinion and blog sites consisting of mostly male authors expectedly have very high percentages of male quotes (e.g. Outsidethebeltway.com, a political opinion blog). Some broadcast news organizations (KQED.org for example) are approaching 50%–50% in male-female gender distributions. On the whole, as a single category, a candidate for a boundary or a component of a boundary may be the gender proportion of 20% female quotes or lower in a political news site.
2. Titles (expert) and non-titles (community) in quotes
In our ground-truthing, the accuracy level of title detection for site content from the Github “Fake News” corpus was low, and hence it may not be possible at this stage to review hypotheses on boundaries that compare disinformation or anti-factual sites with industrialized news sites.
However, there were still some interesting findings with regard to the data for industrialized/big, traditional sites and trade publications. Most high-title proportion sources (90% range) seem to be business, trade, law and finance-markets journals. On these sites, reporters are likely to quote people by expertise (title is a proxy for expertise) in these domains, so it is not surprising to find high-titled vs. non-titled proportions. For traditional news outlets, the titled quotes are in the 60%–75% range, and community quotes in the 25%–40% range, indicating a general “expert bias.” This validates a long-standing critique of mainline journalism that people with titles are quoted a lot more and hence drive the narratives and framing, whereas the lived experiences of community members or “the publics at large” are not represented or elevated as much.
Our observation is that boundary possibilities on the expert-community quotes proportion line are primarily around sector-specific/trade sites vs. mainline news.
3. Proportion of short quotes (< five words)
Originally, we did not have the property “prop_dropped_quotes_too_short” in our dataset. During our initial dataset creation we gathered statistics on the proportion of quotes in a site’s sample article bucket that were < five words and > five words. We started seeing that the mainline news sites were usually in the < 30% short quote proportions whereas some well-known disinformation sites were all ranking ~50% or higher for short quotes. We created this as a new property to examine what was going on. This has been a surprise finding.
Consistently through our experimental runs, many well-known “fake news” disinformation/non-factual sites (e.g. 21stcenturywire.com, thelibertybeacon.com) emerge with excess of 50% of their quotes less than five words long. Whereas almost all the “traditional journalistic” sources are averaging short-length (dropped) quotes well under 30%. This is a big difference. On further investigation we found that sites doing a lot more original reporting, especially local news sites, have even lower percentages of very short quotes. Many known local news organizations have short quotes proportions less than 10%–20%. Mainline news organizations running a lot of reportage and opinion have ranges in the 20%–30%.
Another interesting finding is that sites that are mostly opinion, analysis-only, hyper-partisan, blogs and disinformation appear to be the ones with excess of 50% short quotes. Legal information, trade, advice and special sites also have excess of 50% short quotes.
A few exceptions have emerged. For example, businessinsider.com and democracynow.com have higher percentages of short quotes than the mainline press. It is possible these sites do a lot of curation and rapid newswriting during trending developments, citing other sources and less original people spoken to. Democracy Now does a lot of interviews, and those articles are formatted as interview pages without each voicing out by the interviewee being placed in quotes.
This manual analysis indicates that there is a likely boundary tendency for journalistic behavior around this property. Where news organizations’ reporters are engaged in seeking out people, talking to them and quoting them in a sentence or two in stories, or multiple sentences, at a systematic level, they are producing higher proportions of longer quotes (> five words) and hence their short quotes count is lower. For news organizations’ whose writers are not doing this substantially, or tend to clip quotes to very short key phrases or slogans, they show a greater proportion of shorter quotes.
Automated Data Analysis Findings in the Dataset
To go further from our manual review, we ran feature importance data analysis routines on the dataset to compare sets of sites with differing labels. We used the two sources for site labels:
- MIT dataset: Rating labels from the Media Bias Fact Check news source/site rating effort were crawled by MIT researchers for their own study (Baly et al., 2018) about sites. We cross-tagged the sites in our dataset with their labels–FACTS-High, FACTS-Mixed, and FACTS-Low. These labels help bucket news sites into two broad categories: Those that are committed to some basic journalistic standards and those that are not.
- Fake News Corpus dataset, Github: This archive of news sites (used by researchers) already has a set of labels to tag problematic sites. These are: conspiracy, rumor, junksci, fake, clickbait, hate, unreliable and satire (Szpakowski, 2016).
We used the MIT dataset’s FACTS-High label to select one set of sites, considered more “factual” from our data, and the Fake News corpus labels conspiracy, rumor, junksci, fake, clickbait, hate, unreliable and satire to select another set of sites — which would the problematic set of sites. The latter group was meant to represent sites that produce “news”-like content but may not adhere to journalistic standards.
To automatically determine which features are most associated with the labels, we employ feature importance measures in machine learning. Features that are highly effective in predicting the outcome (e.g., fake news sites vs. factual/legitimate sites) are considered more important. Specifically, we calculate the importance of a feature as the (normalized) total reduction of the Gini impurity brought by that feature. It is also known as the Gini importance, which is one of the most widely used metrics for feature importance. In the implementation, we utilized the feature_importances_ attribute of sklearn.ensemble.ExtraTreesClassifier in the Scikit-learn machine learning library in Python. Our goal was to see which source-diversity and quote properties may be important in predicting one vs. the other type of site. The number of sites in the MBFC/MIT and Fake News site corpuses are relatively small compared to our larger NewsQ and LexisNexis sites lists. Hence our feature importance analysis ran on a smaller subset but clearly labeled set of news sites.
Our findings are summarized below each featured chart we have included. The overall indication is that some properties are better aligned with one or other labels as outcomes. Note: Even though we calculated the values for proportion of articles with named authors (prop_named_authors) and proportion of doubtful speakers (prop_quote_CoreNLP_doubtful_speaker), we are not including them in commentary about the charts in this paper because they are part of future work.
FN-conspiracy (74 sites) vs. MBFC/MIT: Facts-HIGH (162 sites)
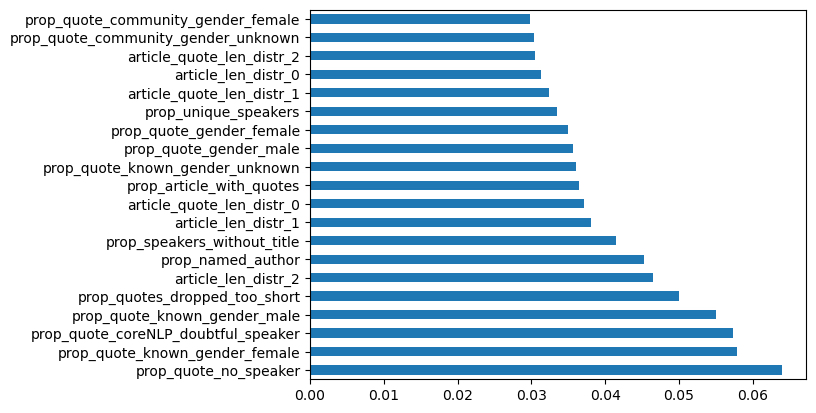
Figure 3: Fake News-conspiracy labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
Explanation: This analysis chart compares 74 conspiracy-labeled sites with 162 high-factuality sites. The highest importance features were: proportion of short quotes and the proportions of quotes around male gender and community (no title)-female gender combinations. Possible behavioral contributors to this are: a) Conspiracy sites are not carrying a lot of original reporting and rely greater on short quotes compared to the higher factuality sites; b) Non-titled/community female quotes are likely lesser in these sites in comparison to mainline sites (even though in mainline journalism female gender quoting is already lesser compared to male); c) Male quotes (prop_quote_known_gender_male and prop_quote_gender_male) are overall driving another distinction between conspiracy sites and high factuality sites. In our manual review we found that disinformation sites had a noticeable higher proportion of male quotes.
FN-clickbait (37 sites) vs. MBFC/MIT: Facts-HIGH (162 sites)
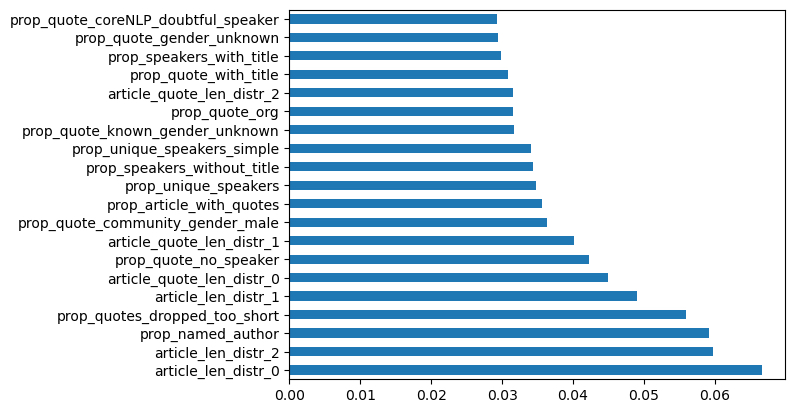
Figure 4: Fake News-clickbait labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
Explanation: In this comparison between clickbait-labeled sites and the high factuality set, the mean and the standard deviation of the article length values, and the short quotes proportions are playing important feature roles in driving distinctions between the sets of sites. This could be because consistently clickbaiting sites do not run long articles as much as the high factuality sites. They are also likely to be doing far less original reporting and instead using clipping bits and pieces of what prominent people may be saying, hence the indication that the shorter quotes proportion is an important feature.
FN-unreliable (42 sites) vs. MBFC/MIT: Facts-HIGH (162 sites)
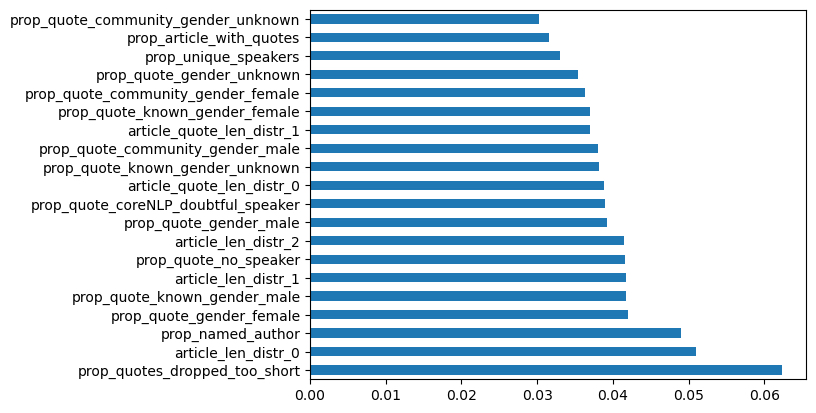
Figure 5: Fake News-unreliable labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
Explanation: “Unreliable” is another human label used for sites in the Fake News corpus. Our observation here is similar to that of the conspiracy sites. Key features driving distinctions between the site sets are shorter quote proportions and gender proportions.
FN-hate (18) vs. MBFC/MIT: Facts-HIGH (162)
Figure 6
Fake News-hate labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
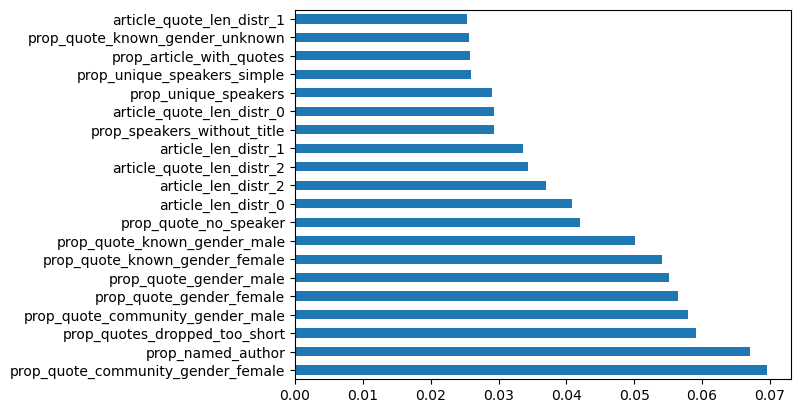
Explanation: This comparison is interesting because the feature analysis is looking at sites labeled as hate sites vs. the high factuality sites. The top feature driving distinctions between the site sets turns out to be the proportion of quotes around gender, and in particular women, without titles — as well as short quotes. It is possible that hate sites quote more prominent women to attack them while at the same time do not quote as many women without title relative to high factuality sites. This comparison itself needs more investigation by increasing the volume of sites in the analysis.
FN-junksci (32) vs. MBFC/MIT: Facts-HIGH (162)
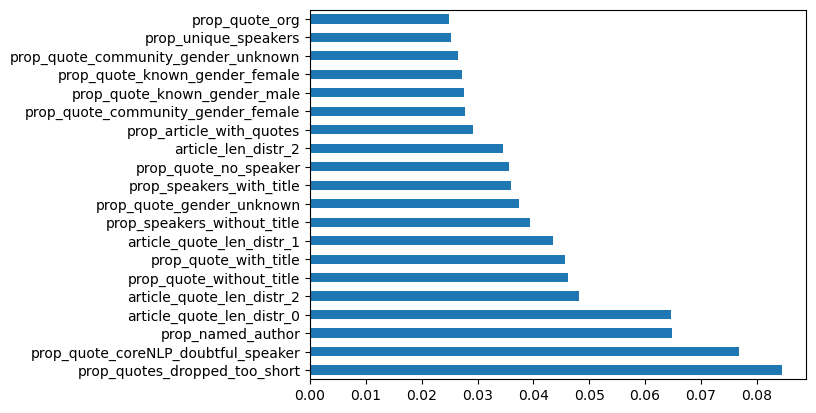
Figure 7: Fake News-junksci labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
Explanation: The junksci label connotes junk science. This comparison is similar to the earlier comparisons on reliance on short quotes, but different in the absence of quote gender proportions as important features. Our explanation is that junk science or pseudoscience sites are types of unreliable sites and hence share some feature importance aspects with those sets of sites. In addition, their quoting practice may not have a strong gender bias to it one way or another, and therefore it does not show up in the highest features by importance.
All fake news label (260 sites) vs. MBFC/MIT: Facts-HIGH (162)
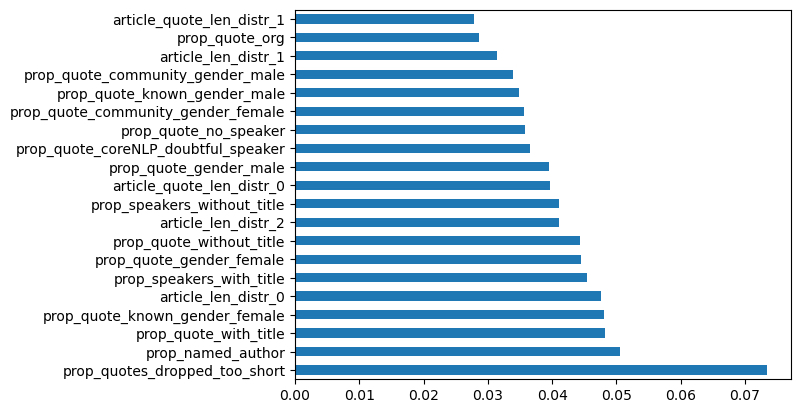
Figure 8 : Fake News-(all) labeled sites vs. High Factuality sites labeled by MIT/MBFC corpus.
Explanation: This analysis compares the union of sites to which the Fake News corpus has attached at least one or more of the problematic labels (conspiracy, unreliable, junksci, etc.) with the high factuality sites. The short quotes proportion is the only key feature here that is at the same relative scale of importance as in the other charts. The proportion of expert (titled) quotes and female titled quotes are showing some significance.
Site Clustering Analysis: Proportion of Female Quotes vs. Short Quotes
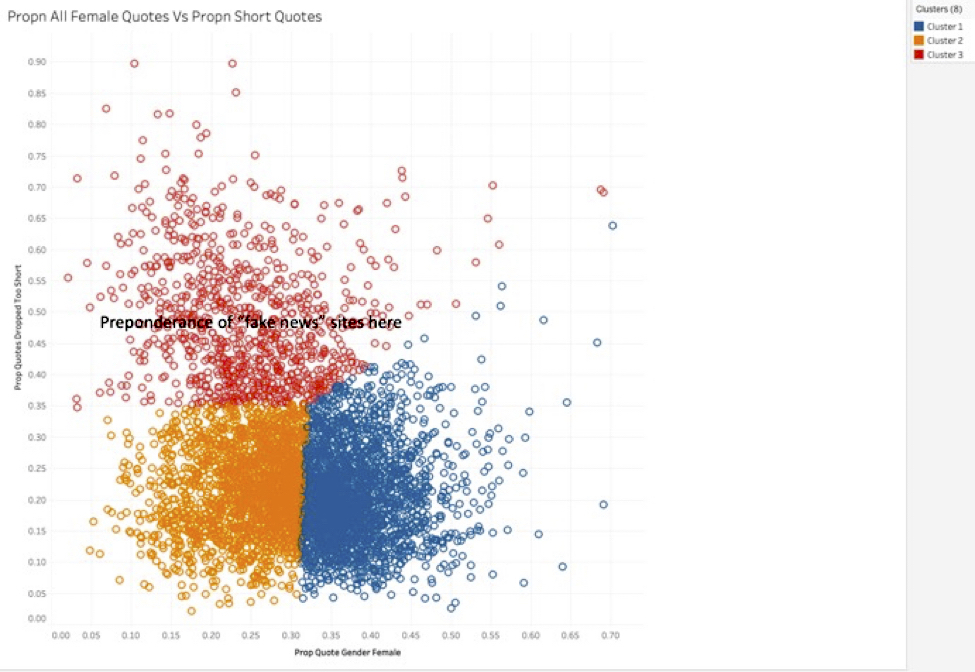
Figure 9: This figure shows the output of a Tableau clustering analysis of the 2,617 sites with 500-article bootstrap-based proportions, around the female quoted proportions vs. very short quotes.
Explanation: We found that a preponderance of disinformation sites were quoting fewer women and using greater proportions of short quotes. Note: “The word Prop(n) in the graphic is short for “proportion.”
Discussion
We began with the hypothesis that quote data proportions from “news-like” websites, if examined for proportionality patterns, will likely have useful signals around the sites’ approaches to journalism. We asked if this may seed a new pathway for a signals-paradigm to center authentic journalistic behavior.
Overall, our observations — from both the manual and automated analysis — are showing that source-diversity and quote proportions data are manifesting possible boundaries between news outlets doing original reporting, hyper-partisan sites, disinformation and conspiracy theory sites, opinion and blog sites, trade publications, and so forth. This validates our hypothesis that creating such datasets would be useful. We make the following list of boundary-related claims.
Claim 1: If the gender proportion of female quotes is 20% or lower, that is a signal to be combined with other data about that site. The central point here is that it is unusual for news stories in (liberal democracies) to be skewed so heavily towards quoting male sources that the proportions exceed 80% male quotes. There is something systematic that is being perpetuated or reflected, which in turn may manifest in other content-related measures for the site.
Claim 2: If the titled quotes proportion is > 90%, the site is likely to be a trade or technical news site, such as foreign exchange, law, stock markets and so forth. Neither disinformation sites nor mainline news sites reach this level of titled quote proportions. As noted earlier, professional journalists inherently lean towards quoting people with title (behavior). But as a wave of new norms is emerging in the profession, local and community news sites are quoting higher proportions of “everyday people.” A skew of over 90% of titled quotes is usually a unique marker of a technical or trade site, or rank elitism, both of which are useful signals.
Claim 3: If the short quotes proportion is > 50%, the site is likely to be mostly a commentary or opinion only site, or a disinformation/conspiracy site — it is a site that very likely does not carry significant original reporting. Conversely, if the short quotes proportions are less than 20%, this indicates more original reporting on the site. Despite its higher costs, original reporting is a key component (not the only) of authentic journalistic work that releases new information to the public sphere. Journalistic endeavors pride themselves on it (see property 29 in “List of per-site properties”).
Claim 4: It is possible to robustly establish site-level quote proportions estimates without the need for large-sized archives (thousands or tens of thousands of stories). Quoting represents a key behavior in journalistic culture. While one way to produce robust quantitative estimates is to operate only on very large archives, this disadvantages rapid scrutiny of low-volume sites that may have recently emerged online. We established that the bootstrap sampling technique can save time and resources and provide accurate enough estimates for both low-volume and high-volume sites.
Applying These Claims
This research makes the case to evaluate boundaries in combination with each other. For instance, sites with higher proportion of female gender quotes and higher proportion of female titled quotes and low proportions of short quotes are very unlikely to be non-journalistic sites. Second, these boundary indications are suited to evaluation for algorithms used on the news platforms as secondary signals to be stacked on top of other data such as topics coverage, author data, etc.
At the higher level, this work surfaces another cross-cutting insight. The question of boundaries is connected to concerns in the literature about “context collapse” online. Current research shows that social media platforms are causing “context collapse” and inattentive processing of news source information (Pearson, 2021). For us, this is one manifestation of the collapse of boundaries as newly produced content flows frictionlessly through the internet platforms. Our findings suggest that technological (data and algorithms) systems could reverse this collapse by adding more layers of domain specific intelligence to algorithmic processing, especially for content from cultural industries like journalism. Drawing from authentic and domain-specific vocabularies in journalism ethics to create datasets and signals is thus a step in that direction.
Limitations and Future Work
Our feature importance analysis is currently done for a smaller set of sites. We plan to expand to increase the number of sites with labels by cross-tabulating data from our news site related dataset sources. We plan to increase all sites to the 500-article or 1,000-sample bootstrap.
To explore more advanced feature analysis, we will apply association rule mining, which can discover interesting associations and correlations between item sets in a large database. We will also utilize clustering algorithm and dimensionality reduction to identify meaningful patterns in an unsupervised learning manner.
A criticism of our approach could be that disinformation sites could invest in making up quotes, longer quotes, etc. Our dataset includes top quoted persons. From a “disinformation-superspreader” perspective, it is possible to convert the extent to which specific people gain prevalence in quotes. By cross-tabulating a site’s top-quoted persons with published disinformation super-spreader lists (for prevalence) the quality of the boundary signals can be enhanced. The extent of speaker plurality could also be an additional area of exploration.
Since summer 2022, our system includes Race/Ethnicity detection system (Shang et al., 2022) for quoted speaker names, with an accuracy of 81% for the White vs. non-White macro classification. We are now able to add a new source-diversity proportionality feature to necessarily complicate the analysis and make it richer.
Finally, video- and audio-only news sources (YouTube news shows and podcasts) are not included in this study.
Conclusion
Source-diversity and quotes data show promise as a basis to identify boundaries between news sites. We reiterate that this is because of the possibility that journalistic sourcing routines are deeper in the reporting practice, and their manifestations may be harder to game by inauthentic journalistic and/or news actors. An absence of specific journalism ethics routines in site actors producing news-like content may be discernible through its corresponding lack of manifestation. Even when present, the degree of manifestation of this behavior may be different enough — in a pattern, across types of journalistic organizations — that it is detectable.
Acknowledgments
We thank Arun Chaganty for advising on the use of Stanford CoreNLP and bootstrap sampling.
References
Bagdouri, M., & Oard, D. W. (2015, October 18-25). Profession-based person search in microblogs: Using seed sets to find journalists. Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 593–602.
Baly, R., Karadzhov, G., Alexandrov, D., Glass, J., & Nakov, P. (2018, October 31-November 4,). Predicting factuality of reporting and bias of news media sources. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium. https://doi.org/10.18653/v1/d18-1389
Carlson, M., & Lewis, S. C. (2015). Boundaries of Journalism. Routledge.
Columbia Journalism School. (n.d.). The objectivity wars [Video]. YouTube. https://www.youtube.com/watch?v=GS0G97eEKb4
De Choudhury, M., Diakopoulos, N., & Naaman, M. (2012, February 11-15). Unfolding the event landscape on Twitter: Classification and exploration of user categories. Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, Washington, United States, 241–244.
Dror, R., Baumer, G., Shlomov, S., & Reichart, R. (2018, July 15-20,. The hitchhiker’s guide to testing statistical significance in natural language processing. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, (Volume 1: Long Papers), Melbourne, Australia. https://doi.org/10.18653/v1/p18-1128
Gans, H. J. (2004). Deciding what’s news. Northwestern University Press.
Manning, C., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S., & McClosky, D. (2014, June 22-27). The Stanford CoreNLP Natural Language Processing Toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, United States. https://doi.org/10.3115/v1/p14-5010
Muzny, G., Fang, M., Chang, A., & Jurafsky, D. (2017, April 3-7). A two-stage sieve approach for quote attribution. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain. https://doi.org/10.18653/v1/e17-1044
News Distribution Ethics Recommendations. (2022). Markkula Center for Applied Ethics. https://www.scu.edu/ethics/nde-2022/
News Quality Initiative. (2020). Resources (Data Collections, API). [Dataset]. https://newsq.net/resources/
Pearson, G. (2021). Sources on social media: Information context collapse and volume of content as predictors of source blindness. New Media & Society, 23(5), 1181–1199. https://doi.org/10.1177/1461444820910505
Shang, X., Peng, Z., Yuan, Q., Khan, S., Xie, L., Fang, Y., & Vincent, S. (2022, July 11-15). Dianes: A DEI audit toolkit for news sources. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain. https://doi.org/10.1145/3477495.3531660
Smyrnaios, N. (2015). Google and the algorithmic infomediation of news. Media Fields Journal, 10(10). http://mediafieldsjournal.org/google-algorithmic-infomedia/2015/11/14/google-and-the-algorithmic-infomediation-of-news.html
SPJ Code of Ethics. (2014). Society of Professional Journalists. https://www.spj.org/ethicscode.asp
Szpakowski, M. (2016–2020). Fake news corpus. [Dataset]. Github.com. https://github.com/several27/FakeNewsCorpus
Vincent, S. (2019, December 18). How might we detect who is and who is not doing journalism online? NewsQ.Net. https://newsq.net/2019/12/18/how-might-we-detect-who-is-and-who-is-not-doing-journalism-online/
Vincent, S. (2020). Understanding the demand-side of misinformation and analyzing solutions. In R. Chun & S. J. Drucker (Eds.). Fake news: Real issues in modern communication (pp. 57–81). Peter Lang. https://www.peterlang.com/document/1111222
Vincent, S. (2023). Reorienting journalism to favor democratic agency. In P. Ellis & P. Dallas (Eds.). Reinventing journalism to strengthen democracy (forthcoming). Kettering Foundation.
WAVE Research Projects (2022). Santa Clara University. https://www.scu.edu/wave/wave-research-projects/
Webz.io. (2020). Explore news articles that mention “CoronaVirus”. [Dataset].
https://webz.io/free-datasets/news-articles-that-mention-corona-virus/
Zeng, L., Dailey, D., Mohamed, O., Starbird, K., & Spiro, E. S. (2019, June 11-14). Detecting journalism in the age of social media: Three experiments in classifying journalists on Twitter. Proceedings of the International AAAI Conference on Web and Social Media, Munich, Germany, 13(01), 548–559. https://doi.org/10.1609/icwsm.v13i01.3352
Appendix: More on Methodology
Appendix A1: More details on how we created the dataset
As noted the paper we used three corpora of news archives. Of these, the Webhose.io and Lexis Nexis corpora have very few “fake news” or known “disinformation sites”, that are listed in the NewsQ sites database. The Github Fake News corpus has over 700 sources cross-listed in NewsQ. A combination of the three corpora is represented in our final sites dataset. We examined the corpus formats (JSON text files) and built software routines to pull the news articles into a local filesystem. We designed customized jobs for large scale extraction (1K, 10k, 20k, 100k, 300k, and 2M articles). Our tactical goal for the study was also to complement NewsQ’s U.S. sites dataset that already has around a 100 properties per site, with new site-level properties around journalism ethics and quotes. (Vincent, 2019).
Appendix A2: More details on processing pipeline to deliver quotes data
- Extraction: We used corpora that have been derived with different methods of crawling and extractions. Lexis Nexis is a proprietary system whose extraction routines (from the web) we have no visibility into. We processed the archive feeds files of 3TB size spanning 92 days. The Fake News Github corpus uses Scrapy, a well-known website crawler. Webhose.io uses its own crawlers. Reviewing data for the same news source from different corpora makes our validation of the annotation system more robust.
- NLP annotation for quotes data: We used Stanford CoreNLP 4.0.0 release along with several of its built-in annotators for ingesting articles. The named entity recognizer (NER), quote, quote attribution, and key relations annotators are the critical ones.
- Database setup: We used a Postgres SQL Server to store and process all extracted data. We also used the server to configure, store, and control massive parallel computational jobs.
- Preprocessing:
-
- We eliminated quotes less than five words long to increase overall accuracy of speaker resolution. (See property 29 in the dataset section for more.)
- We also eliminated open quotes (quotes where the closing ‘ “ ‘ was missing).
- We excluded very small articles—typically video only articles which often don’t have any other reporting—using a 30-word minimum length filter.
- We used a maximum paragraph length limit of 500 words to eliminate rare crawling errors or HTML format errors which would confuse the CoreNLP annotation system.
- Photo captions have names in them and we found that would increase the inaccuracy of quote to speaker resolution when the quotes were coincidentally too close to the captions. We used a photo caption pattern match to eliminate caption text less than or equal to 50 words in length. (Patterns: “PHOTO:” “Photo:” “Image:” “Image source:” “Gettyimages” “Video:” “Picture::”)
Appendix B: List of per-site properties for the dataset
Below are the final list of 29 source-diversity, quotes and article related properties we created at the news-site level in our dataset.
- article_num: Total number of articles processed for a particular proportion calculation job (e.g. 500 articles from each site).
- prop_named_author: Proportion of articles with byline (named author) vs. without. This property has substantial promise or consideration in future work, but we did not use it in for our current analysis because of inconsistent metadata about author naming across the news archive formats.
For the rest of the property definitions below, valid quotes are quotes of length > = five words. Short or dropped quotes are quotes of length less than five words (property #29).
- article_num_with_quotes: The number of articles in analyzed sample which has at least one quote.
- avg_quotes_per_article: total valid quotes number/total articles.
- prop_article_with_quotes: article_num_with_quotes/the number of total articles.
- article_len_distr: Mean, media and standard-deviation of article-word-lengths in article sample.
- article_quote_len_distr: Mean, media and standard-deviation of quote-word-lengths in article sample.
- prop_unique_speakers_simple: (Total unique quoted-speakers-all articles/the number of total valid quotes with speaker) x (prop_article_with_quotes).
Definition of unique = SIMPLE: Just the same full names, identical match.
- prop_unique_speakers: (Total unique quoted-speakers-all articles/the number of total valid quotes with speaker) x (prop_article_with_quotes).
Definition of unique: Two full names are identical, AND BOTH organization and title are above our similarity threshold.
- top_quoted_persons_simple: Top #n quoted Persons in the source’s article samples.
Definition of unique = SIMPLE: Just the same full names, identical match.
- top_quoted_persons: Top #n quoted Persons in the source’s article samples.
Definition of unique: Two full names are identical, AND BOTH organization and title are above a similarity threshold (algo).
- prop_quotes_with_title: the number of quotes where speaker has title/the number of total valid quotes with speaker.
(The title related properties starting at 12, and going down, are in a category called Known vs. Unknown in journalism ethics [Gans, 2004]).
- prop_quotes_without_title: the number of quotes where speaker has NO title/the number of total valid quotes with speaker.
- prop_speakers_with_title: the number of unique speakers with title/the total number of unique speakers.
- prop_speakers_without_title: the number of unique speakers without NO title/the total number of unique speakers.
- prop_quotes_gender_female: the number of quotes which gender is female/the number of total valid quotes with speaker.
- prop_quotes_gender_male: the number of quotes which gender is male/the number of total valid quotes with speaker.
- prop_quotes_gender_unknown: the number of quotes which gender is unknown/the number of total valid quotes with speaker.
- prop_quotes_known_gender_female: the number of quotes which has title and gender is female/the number of total valid quotes with speaker and with title.
- prop_quotes_known_gender_male: the number of quotes which has title and gender is male/the number of total valid quotes with speaker and with title.
- prop_quotes_known_gender_unknown: the number of quotes which has title and gender is unknown / the number of total valid quotes with speaker and with title
- prop_quotes_community_gender_female: the number of quotes with NO title and gender is female/the number of total valid quotes with speaker and without title.
- prop_quotes_community_gender_male: the number of quotes with NO title and gender is male/the number of total valid quotes with speaker and without title.
- prop_quotes_community_gender_unknown: the number of quotes with NO title and gender is unknown/the number of total valid quotes with speaker and without title.
- prop_quote_orgs: the number of quotes which has a related organization/the number of total valid quotes with speaker.
- top_quoted_orgs: Top #n quoted Orgs in the source’s article samples.
Note: Not used in our analysis for this paper.
- prop_quotes_no_speaker: the number of quotes which has NO speaker/the number of total valid quotes.
Note: This is experimental/noisy, may include anonymous quotes and unresolved quotes.
- prop_quotes_coreNLP_doubtful_speaker: the number of quotes which has doubtful speaker/the number of total valid quotes with speaker.
“Doubtful speaker” data: In our ground-truth experiments, we discovered that some CoreNLP diagnostic values (mention_sieve, speaker_sieve, [Muzny et al., 2017]), the canonical/speaker name status, and our detection level for quoted (paragraph level or article level) fell into a combination of four particular patterns every time the speaker for a quote was wrongly resolved. We create four mini-rules for this, RULE1 or RULE2 OR RULE3 OR RULE4. In our at scale computations, quote-to-name resolution matching one of these rules are flagged as “doubtful speaker”. We used these rules to eliminate such quotes and increase accuracy for name and title resolutions. This is a diagnostic property only. It may only usable for boundary analysis if very large swings of this value are present across news sources or if advanced data analysis methods indicate the features are important.
- prop_quotes_dropped_too_short: the number of quotes less than five words in length/(the number of total valid quotes + total quotes less than five words in length).
About the authors:
Subramaniam Vincent is Director of Journalism and Media Ethics at the Markkula Center for Applied Ethics, Santa Clara University. His focus is on developing tools and frameworks to help advance new norms in journalism practice and ethical news product design.
Xuyang Wu is currently a Ph.D. student at the Department of Computer Science and Engineering, Santa Clara University. His research interests include natural language processing, deep learning and data science on information retrieval and recommendation systems.
Maxwell Huang is a junior at Monte Vista High School, Danville, CA. Yi Fang is Associate Professor of Computer Science and Engineering at Santa Clara University with substantial interests in Information Retrieval and NLP.