
Algorithmic Agenda Setting: The Shape of Search Media During the 2020 US Election
By Daniel Trielli and Nicholas Diakopoulos
[Citation: Trielli, D. & Diakopoulos, N. (2022). Algorithmic agenda setting: The shape of search media during the 2020 U.S. election. #ISOJ Journal, 12(1), 45-70]An algorithm audit of results during the 2020 United States presidential election investigates the agenda of topics and issues curated by Google search about the two main candidates. This work is framed around the agenda-setting understanding that public opinion is shaped by the salience of issues in the media, and search, as an extension of that media ecosystem, should be evaluated through the same lens. This study asks: to what extent do the topics selected by search media replicate the agenda of the news media? And to what extent does searcher input alter these topics? The results show the differences between the topics in news media and in the search engine and a limited power by the user to reshape the topics in the search results. These findings elaborate an understanding of how search media can drive, shape, or counteract choices made by news media and search users.
Search engines are an integral part of the system of distribution of news information to the public (Bandy & Diakopoulos, 2020; Bentley et al., 2019; Diakopoulos, 2019; Trielli & Diakopoulos, 2019) and, as such, a significant new piece in the process of selection and emphasis of issues in the media. The Artificial Intelligence-driven curation of search media (Metaxa et al., 2019) has the potential to influence public opinion in political and social domains (Epstein & Robertson, 2015; Epstein, 2018; Kay et al., 2015), and exercises power by shaping how the public makes informed political choices (Dutton & Reisdorf, 2017; Knobloch-Westerwick et al., 2015), including what and how issues are presented during elections (Diakopoulos et al., 2018; Muddiman, 2013; Trevisan et al., 2016).
Public opinion is shaped by the salience of issues in the media, an idea that is at the heart of agenda-setting theory. This theory states that the salience that the media provides certain topics is associated with the importance that the public attributes to the issues reflected by these topics (McCombs & Shaw, 1972; Scheufele & Tewksbury, 2006; Valenzuela, 2019). With search now being an extension of how news media is distributed, the way its algorithms select and shape topics gains importance and warrants scrutiny (Mustafaraj et al., 2020; Whyte, 2016).
This study investigates the agenda of topics and issues that are curated by the Google search engine in the context of the 2020 U.S. presidential election. We investigate the salience of topics in search media, by pursuing two research questions: first, to what extent does the distribution of topics selected by search media replicate the agenda of the news media? And second, to what extent does searcher input (i.e., a user’s specific selection of query terms) alter this distribution?
Addressing these two questions offers insight into how Google search acts as a curator of topics related to newsworthy queries. Firstly, if Google simply replicates the agenda of news media, this would signify a strong dependence on that news content. But differences in the distribution of topics between search and news media implies either dependence on other sources of information (candidate websites, blogs, other websites) or Google’s editorial selection on those topics. Benchmarking this similarity, and translating it into dependence is difficult, since doing so depends on normative expectations of representativeness of news media in search results. However, we can calculate the degrees of similarity across topics to obtain an internal comparison of dependence on news media across them. Additionally, we can measure how that representativeness shifts with user input, which is related to the second question: To what degree does the Google search engine react to the inclusion of a modifier in the query by adjusting the results accordingly? At stake here is an assessment of the relative power of the user versus the news media in setting the agenda of exposure, a tradeoff which is mediated by the algorithms driving Google’s search engine (see Figure 1).
Figure 1
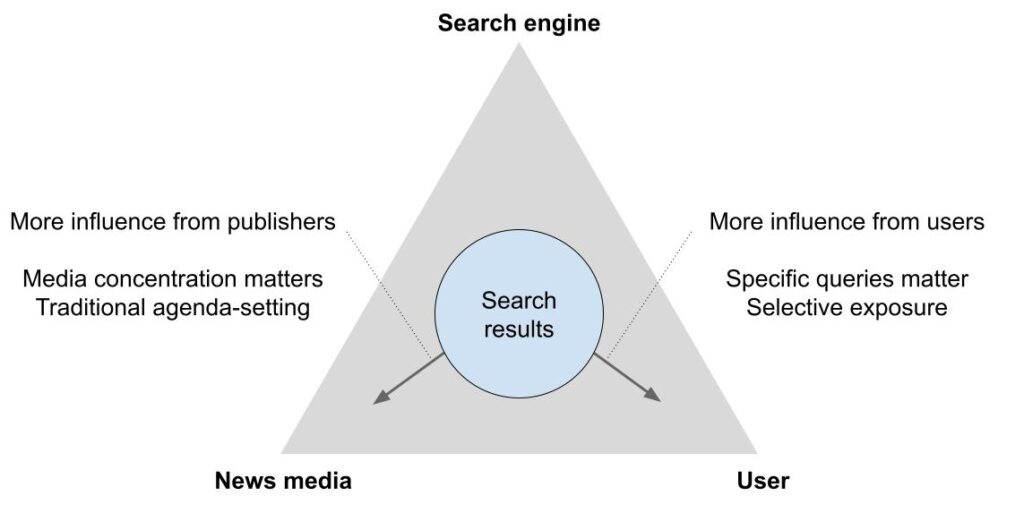
To address these questions, we conducted an algorithm audit of Google search, comparing topics in news media articles about the two main presidential candidates in 2020 with topics that emerged in searches for the candidate names in the same timeframe. We found that while the relative rankings of prevalence of topics are correlated between the two datasets, there are divergences in the prevalence of those topics too. This suggests some overall congruence between the shape of search and news agendas while also indicating differences in the specific weight Google gave to topics in comparison to news media. We also found that, as expected, the inclusion of specific topic modifiers in the queries could reshape the topics of the results. However, there were also instances where this wasn’t the case, in which user input alone did not drastically reshape the salience of topics.
Our findings advance a better empirical understanding of the relationship between search engine and news media, and to the connections and tensions between algorithms, journalism, and the democratic role of new AI-curated media (Helberger, 2019). We further discuss implications for news media in terms of how to influence the search agenda via third-level agenda-setting and elaborate how our methodological approach of looking at content, rather than sources, is a promising avenue for future work studying AI-driven curation systems at scale.
Related Work
In this study, we establish a connection between previous work on search engines and news—particularly political news—as well as agenda-setting theory and its implications for digital media. In the following subsections we describe previous work in these areas.
Search Engines, Politics, and News
The importance of search engines to the process of political information distribution and seeking has motivated extensive research in the last few years. A majority of people go to search engines first when they are seeking political information (Dutton & Reisdorf, 2017). In sessions of internet use that include news reading, 20% start with search engine use, compared with 16% for social media (Bentley et al., 2019). Search media is especially important for political contexts (Metaxa et al., 2019), and this importance is closely related to the trust that audiences have in search engines (Pan et al., 2007).
Search results are co-constructed by the search engine’s algorithmic curation and the searcher’s demands. Searchers bring their own preconceptions to this transaction, and those preconceptions can be reinforced by the search engine (White, 2013; White & Horvitz, 2015). In the case of politics, voters have broad information needs and varied prior knowledge, and not considering those perspectives in search engine audits leads to failure to measure important aspects of quality of search results such as the bias of results that are generated both by the search engine curation and the input bias of users as well as the presence of pollution in the ecosystem of information (Mustafaraj et al., 2020).
Much of the research on the connection between search and politics and news has focused on search engine audits that try to measure bias and personalization of results, with a focus on disparate curation of partisan information (Hu et al., 2019; Kulshrestha et al., 2019). Results show partisanship can be amplified by some elements of search results, such as snippets of text (Hu et al., 2019), and that the presence of candidate–controlled sources in search results increases positive bias towards the candidate (Diakopoulos et al., 2018; Kulshrestha et al., 2019; Puschmann, 2018).
While studies have found limited political bias of search results generated from platform personalization (Kliman-Silver et al., 2015), there is nonetheless bias exhibited in terms of selected mainstream sources (Courtois et al., 2018; Trielli & Diakopoulos, 2019). That mainstreaming effect is also resistant to user input: previous work has matched surveys of search queries to search results and found that Google partially neutralizes differentiation of search behaviors across different political groups (Trielli & Diakopoulos, 2020). While even a mainstream news media selection can reflect an improved and more diverse news consumption for some users on the individual level (Fletcher & Nielsen, 2018), previous work has highlighted that concentration of media audiences into a small number of news websites that are cooperative to tech intermediaries can negatively affect society-wide perspectives to news information (Smyrnaios, 2015).
Some of the biases found by research on Google search were also uncovered on another Google service, Google News. Just as in Google search, previous work has encountered dominance of highly frequented and national outlets over local outlets in Google News (Fischer et al., 2020; Haim et al., 2018). In terms of agenda-setting, Google News, being a repository of news articles, tends to replicate traditional industry structures, according to a study that asked real-world participants to use Google News to search for information about U.S. presidential candidates in the 2016 election (Nechushtai & Lewis, 2019). As in research on Google search, this study found little variation of curation across political identities of users, weakening the argument of filter bubbles in Google News (Nechushtai & Lewis, 2019). However, other work that used sock-puppet accounts to simulate use of the platform has noticed some political personalization based on browser history (Le et al., 2019).
Methodologically, these studies are complicated by the variety of factors in the act of using search engines that are within and beyond the control of the searcher (Ørmen, 2016). Furthermore, whether previous research has investigated Google search or Google News, the unit of analysis of these studies is typically either the specific web pages or sources that are represented in the search results. Little attention has been given to the content of those websites, and their representation as a reflection of topics. In this study, we examine the topical content of the web pages that are represented in search results as another important avenue to measure potential search bias. That is because the salience of topics represented in media is relevant to political information and public discourse, as articulated by agenda-setting theory, which we elaborate further next.
From Agenda-Setting Theory to Search Media
Agenda-setting theory reflects the idea that mass media influences the salience of issues in the public debate (McCombs & Shaw, 1972). According to this proposition, in determining what topics to cover, news organizations signal what topics are important and worthy of attention. News audiences, by consequence, learn how much importance to attach to certain topics (McCombs & Shaw, 1972), and topics that are more salient in the news media are considered to be more important in the public opinion as well (Valenzuela, 2019).
As new media started to appear and expand after the theory was proposed in the 1970s, agenda-setting theory has continued to expand and be refined (Valenzuela, 2019). One such expansion was the development of second-level agenda-setting, which connects to the idea of framing. Framing describes how a topic is presented in news media (Scheufele & Tewksbury, 2006) such as through the choice and usage of words, and second-level agenda-setting explores how that framing impacts the public agenda (McCombs et al., 1997). Specifically using the terms used in the description of this theory, first-level agenda-setting communicates the salience of topics in the news and second-level agenda-setting communicates the attributes of those topics. Finally, there is the third-level of agenda-setting, which examines how news media not only transfers the salience of topics and their attributes, but also the relationships between those topics (Guo & McCombs, 2011). This idea of networked agenda-setting is that news media also makes associations and relationships among different topics, and that has an influence on the public’s cognitive picture (Wu & Guo, 2020).
The agenda-setting framework has previously been used to investigate digital media, particularly social media. Studies on fake news, for instance, have been able to make connections between agendas of traditional media, disinformation websites, and fact-checkers using the framework of networked agenda-setting, and have attempted to predict when other agendas overlap between these media outlets (Vargo et al., 2018). The new possibilities of data availability are particularly salient in studies that focus on social media, which also highlight how agenda-setting is transformed by the advent of audiences who are also producers of media (Groshek & Groshek, 2013). Research has found a symbiotic relationship between social media and traditional media (Conway et al., 2015; Groshek & Groshek, 2013). Studies that compare content produced by audiences with the content of news media have shown that while the dynamics of attention in both types of media are similar, there are different rhythms of attention at play (Neuman et al., 2014).
While social media has been the focus of several agenda-setting theory studies in digital media, search media has been less investigated, despite clear applicability and opportunity for study. Search engines are clearly a venue to explore topics and agendas, representing a place of connection between different agendas from different agents of communication. Search media is co-constructed by the user who searches, the algorithm that computes relevance, and the underlying material that is found. Previous work has shown that Google web search such as search volume represented in Google Trends can be a viable source of analysis for social science research, both because it serves as a proxy for public opinion and as a good measurement for the impact of political campaigns on local interest in a topic (Whyte, 2016). In this study, we take this literature further by developing a method through which topics can be analyzed in search media.
Method
To answer whether the distribution of topics in search engines replicates the agenda of news media and how users can alter that distribution, we conducted a two-step algorithm audit. In the first step, we compare two datasets relating to our target subject, the 2020 U.S. presidential campaign. The first dataset reflects the topics in search results that are retrieved from searching the names of the presidential candidates; the second dataset is a baseline constituted from a broad sample of news articles that mention the candidates during the same timeframe. In the second step, we conducted another comparison, but this time between the results of a straightforward name search and a modified search that also contained topics of interest during the election. In the next subsections, we describe this method in more detail, including how we collected and analyzed this data.
Data Collection and Preparation
Search results were collected and parsed using the WebSearcher package (Roberston & Wilson, 2020). The automated searches were done on Google.com using a desktop browser configured with no user history, without being logged-in, and with language set to English, using a server located in Ohio. The searches were conducted during the general election period in 2020, from September 3 to November 3, 2020. This timeframe begins shortly after the nominating conventions and continues until election day. Searches were repeated every hour because news-related search results tend to have a relatively quick turn-over (Trielli & Diakopoulos, 2019).
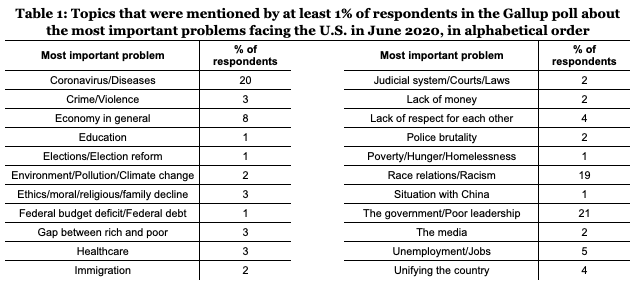
To cover our two questions—the first about general searches about candidates and the second about searches paired with modifiers representing searcher interest in a topic—we conducted two types of searches simultaneously. For the first question, we searched and scraped the top 10 organic search results (search results that are neither ads nor links in widgets on the results page, such as the “In the News” box) for the queries Joe Biden and Donald Trump. These queries were not exact queries enclosed in quotes, which we argue is how a searcher might write a casual, general query. For the second question, we searched for each candidate name combined with specific topics of interest in the elections (again with the names and the topics not enclosed in quotes, e.g., Joe Biden Healthcare). By doing so we prod the search engine to provide different results based on a specific change in the query input. To come up with a list of such topics, we used Gallup’s Most Important Problem survey1, which asks Americans every month what they think is the most important problem facing the country. This survey has long been used to measure the public agenda (Edy & Meirick, 2018; McCombs & Zhu, 1995). An alternative approach would be to extract topics of interest using Google Trends (Whyte, 2016), which has partial correlation with the results from the Gallup poll (Mellon, 2014). However, while Google Trends is a viable source of political communication research (Whyte, 2016), the goal of our study was to measure the representativeness of the public agenda directly in the search media, without confounding this comparison with metrics of search volume. For June 2020, we collected data for 22 topics that at least 1% of respondents in the Gallup survey considered the most important problems (see Table 1). In the queries we used the same words used to describe each problem, only excluding the slash between them (e.g., Donald Trump Coronavirus Diseases).
We compare the datasets of search results with a baseline of news stories extracted from Media Cloud, an open-source platform that tracks and collects metadata about the online media ecosystem, including an extensive database of links to news articles (Roberts et al., 2021). Media Cloud allows searches in its database over specific collections of sources. We selected two collections that encompass the main news media organizations in the United States: U.S. Top Newspapers 2018 (50 media sources) and U.S. Top Digital Native Sources 2018 (37 media sources)2 and collected all the links from these media sources that mention either one of the two main presidential candidates in the 2020 U.S. presidential election, Donald Trump and Joe Biden. The timeframe for that collection matches the collection of search results—September 3 to November 3, 2020.
The search results both for the general and the topic searches yielded a total of 2,158 unique URLs that belong to 466 domains. There are 167 URLs for general search terms (across 34 domains) and 2,019 URLs for topic searches (across 461 domains)—28 of those URLs appear in both general and topic searches, as well as 29 domains (some domains repeat between the two types of searches with different URLs). The full baseline of news articles consisted of 27,663 unique URLs (across 87 domains), of which 27,073 had recoverable texts that mentioned either Donald Trump or Joe Biden. Of these 27,073 news articles, 96% contained reference to Donald Trump and 64% to Joe Biden. For the comparison between search results and news media, the news media baseline dataset is further split into two, one baseline for Trump news stories (25,968 news articles) and one baseline for Biden news stories (17,208 news articles).
With the two lists of article links at hand (i.e., search results and news media baseline), we then scraped the article text of each of the links3. This was necessary so that we could extract the topics from the content of each search result. The topic extraction process is described in the following section.
Data Analysis
The two questions we aim to answer with this analysis are: 1) To what extent does the distribution of topics selected by search engines replicate the agenda of the news media?; and 2) to what extent does searcher input in the form of topic-related query elaborations alter this distribution? To address these questions, we developed a method that compares topics extracted from our collection and baseline.
To compute the topics from the content of the links collected both in the Google search results scrape and the baseline news media from Media Cloud, we used the NYT–Based News Tagger4, which is also used by Media Cloud to conduct its analyses. This machine-learning (ML) based labeler was trained on a corpus of 1,800,000 texts from The New York Times. It returns various labels that are descriptors and taxonomic classifiers based on five different models in which different sets of descriptors are used. These labels were originally created by The New York Times to describe its own corpus5. The most accurate of the ML labeling models, according to the documentation (Rubinovitz, 2017), is one that uses the 600 most common descriptors in the corpus6. This is the model that we used to extract the labels in each text in our baseline and search results datasets.
The model tags each text with up to 30 descriptor labels, and each of those labels is accompanied by a confidence score, from 0 to 1. Therefore, each text typically has multiple labels with varying levels of confidence. Not all 600 descriptors were represented in the datasets: 575 of the 600 labels were detected in the datasets. However, for most texts there are labels with a confidence score below 0.5. For our analysis, we exclude these labels since they indicate less certainty in their validity. After filtering out the labels that were below the 0.5 confidence threshold, there were 330 distinct labels.
Even with the imposition of the threshold of a confidence score of 0.5 or higher, there still remained the question whether those labels were accurate. To evaluate the accuracy of labels, we extracted a random sample of 100 texts from the search results dataset and the first author manually reviewed the appropriateness of the labels. Those 100 texts had a combined total of 276 labels that had a confidence score higher than 0.5; of those, 248 (89.9%) were appropriate, indicating that the 0.5 threshold yields labels with high accuracy. We repeated this process using another 100 articles randomly sampled from the media baselines and found that 206 of 235 labels (90.4%) with a confidence higher than 0.5 were appropriate.
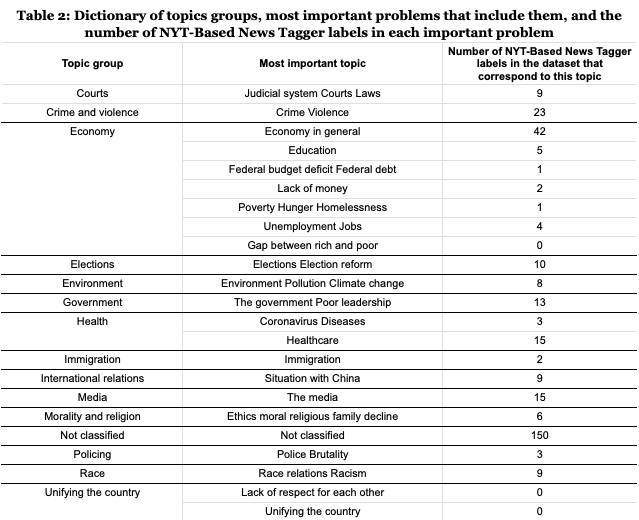
The next task was to transform those labels into larger aggregations that reflect topics. To do so, we again resorted to the Gallup survey of the most important problems in the election. We manually developed a dictionary of topic groups that approximately maps between the set of 330 labels in the NYT–Based News Tagger and the 22 most important problems from the Gallup survey. However, in some cases, we collapsed the Gallup problems into a higher level group in order to more robustly capture the underlying topics that both these labels and this classification of problems describe. Some labels were broader than most important problems. For instance, “Lack of money” and “Gap between rich and poor” are mentioned as two of the most important problems in the elections according to Gallup. While socio–politically they imply different issues, they both might be described by the label “wages and salaries” which is a label produced by the News Tagger. Some interpretations from the news articles themselves were also used to inform the mapping. For instance, the most important problem “Situation with China” was renamed with the News Tagger label name “International Relations,” since that is a more general description of the issues to which those news stories relate, and this facilitates measuring with a broader array of labels from the News Tagger.
Another issue is that some labels present in the datasets are not represented in the most important problems surveyed by Gallup. For instance, labels that mentioned art and culture, such as “books and literature” and sports, such as “superbowl” had no corresponding category in the most important problems. In the dictionary, these are marked as “Not classified”. They correspond to 45% of the number of detected labels from the NYT–Based News Tagger, but when considering the number of times that the labels appeared in the dataset, they only represent 17% of the volume of labels identified in the search results collection dataset.
This process yielded 13 substantive topic groups mapped to 180 labels from the News Tagger. The final dictionary (of which there is a summary in Table 2) allows us to create comparisons between the themes that emerged and their relative importance to the public. To conduct our analysis, we calculated and compared the prevalence of the topic groups across each dataset. Because one of the topic groups yielded no labels (“Unifying the Country”), we removed it from subsequent analyses. To address the first research question, we calculated the similarity of general search results and the news media baseline, both by calculating the similarity of distributions with chi-square testing for independence, and then by assessing similarity of the relative distribution of topic groups using Spearman correlations. To address the second research question we conducted an analysis of the topic searches (i.e., candidate names + topic) by comparing the topic groups of those results to the topic groups in general searches (i.e., just candidate names). We then calculated the ranking similarity of the distribution of topics via the Spearman correlation.
Results
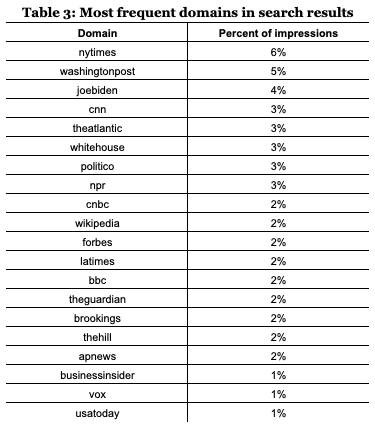
From the top 20 most frequent domains represented in the search results (see Table 3), 16 belong to the news media, which indicates the importance of news media in establishing the agenda of search media. The exceptions were the websites that belong to Joe Biden’s presidential campaign, the White House (then the official website for President Donald Trump), Wikipedia, and the Brookings Institute. These results also confirm previous findings indicating the skewed distribution of Google results toward the top sources (Muddiman, 2013; Trielli & Diakopoulos, 2019). Of the 466 domains, the top 4% corresponding to the 19 biggest sources of search results account for 50% of the appearances of links.
In the following sections we elaborate analyses corresponding to each of our two research questions.
First Step: General (Name) Searches
Our first research question asks whether the distribution of topics in search results corresponds to the distribution of topics of the news media in the same period. To conduct our analysis, we calculated the prevalence of each topic group in each dataset by counting the labels assigned to each of the articles that were associated with that topic group. Table 4 shows the most frequent topic groups for Donald Trump and Joe Biden in comparison to the news media baseline.
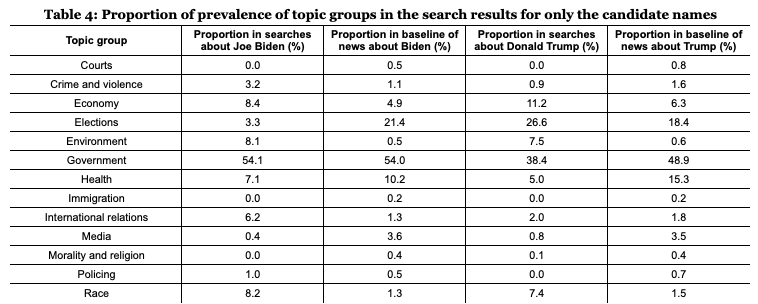
The results from Table 4 show, at a glance, some differences between the proportions of individual topics in search results and news media. For instance, there are salient differences when it comes to the topics of Race or Environment (underrepresented in the baselines as opposed to the candidate search results) and Health (overrepresented in the baseline as opposed to the candidate search results). And there can be wide variance in the proportion of topics with respect to either candidate such as the Elections topic which appears in 3.3% of search results for Joe Biden but represents 26.6% for search results about Donald Trump. Moreover, the search engine can boost the prevalence of a topic for one candidate while diminishing it for the other, such as for the Elections (diminished for Biden, boosted for Trump) or Crime and Violence topics (boosted for Biden but diminished for Trump).
To quantitatively assess the relationship between the relative distributions of topics, we calculated the Spearman correlation between the proportions of search result topics and the baseline news media topics. The Spearman correlation coefficient is a measurement of the similarity between two rankings. In this case, the rankings are defined by the prevalence of topics in the search results sample and the prevalence of topics in the baseline news media sample about the candidates in the same period. The higher the correlation coefficient (between 0 and 1), the more similar the relative distribution of topics between the two datasets. The Spearman correlations show some congruity between the news media topic selection and the search engine topic selection, and little difference between candidates: for Biden, the Spearman rho was 0.707 (p = 0.007) and for Trump, 0.713 (p = 0.006).
As previously mentioned, benchmarking similarity between topics depends on normative expectations of representativeness of news media in search results. However, we can calculate the degrees of similarity across topics to further assess the relationship between the prevalence of each topic for each dataset. We conduct chi-square tests for independence of the counts of the labels assigned to each of the articles that were associated with topic groups. For the comparison of both Biden’s and Trump’s search results with the news media baseline, the distributions were significantly different (Biden: 𝛘2(12, N = 42,934) = 3,951.06, p < .001; Trump: 𝛘2(12, N = 54,849) = 2,461.35, p < .001). These results indicate divergence in the proportion of individual topics, consistent with observations in Table 4. So, while the Spearman results indicate that the relative rankings of topic groups based on their prevalence are correlated, the chi-square results indicated divergence in the distribution of topic groups. In other words, the relative attention given to different topics in the agenda is fairly stable but the specific proportion of attention given to different topics differs.
Second Step: Topic Searches
In order to examine our second research question related to the extent to which user input alters the distribution of topics, we first describe those distributions and then again calculate the Spearman correlation of topic rankings. However, this time, instead of comparing search results with news media, we compare search results from generic searches (i.e., candidate name) with topic-specific searches (i.e., candidate name + topic) corresponding to each of the 22 most important problems from the Gallup survey. In Tables 5 and 6, we see how the search queries impact the distribution of topics in the search results. The first row of each table shows the proportions for the general (name) searches and the subsequent rows show the proportions for the searches altered for each of the 22 most important problems.
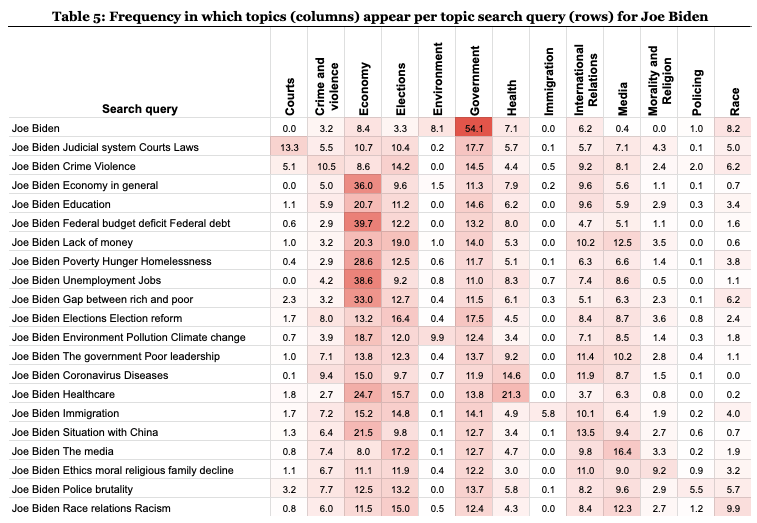
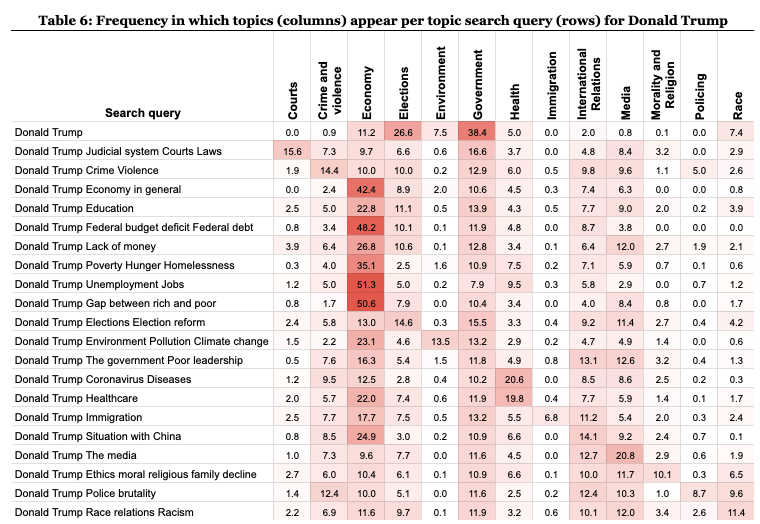
As we see, the inclusion of topics in queries defined by the user appears to change some distributions. At first glance, these shifts reflect that the search engine is working as expected: matching the user interest with new results about the topics they search. But the results paint a far more complex picture too. For instance, the relative weight of the topic of Government, which is the most prominent in the general searches, decreases by a large margin when any topics are included in the search. On the other hand, the topic of Elections is boosted by any topic search for Biden but reduced by any topic search for Trump including for the query most expected to be boosted (Donald Trump Elections Election reform). Another distinctive change is in the distributions of topics around the Economy. For Joe Biden, adding almost any modifier in the searches increases the proportion of content about the economy (with the exception of the search Joe Biden the media. For Donald Trump, 16 of the 20 query modifiers also increase that proportion.
In other topics, the effect is minimal across the board. The topic of Environment, which represents 8.1% in generic searches for Biden and 7.5% for Trump, only goes up to 9.9% and 13.5% when specifically mentioned in the topic searches. But in all other topic searches the Environment topic markedly decreases. Additionally, some topics only appear when specifically searched on by the user. This is the case for Immigration, which goes from 0% of topics in the general searches for both candidates to 5.8% with topic–specific searches for Biden and 6.8% for Trump. And so while Google search unsurprisingly works to adapt the topics based on the query, it’s also interesting to consider what topics are left out in the baseline agenda, and the degree to which user input can shift away from that baseline. On average, the inclusion of a topic in a query increases the prevalence of that topic by 11 percentage points for Biden (SD: 15) and 14.4 percentage points for Trump (SD: 16), but for some topics the change can be as high as 40.1%, such as for the impact on Trump Economy results of a Donald Trump Unemployment Jobs search, or as minimal as just 1.8%, such as for the impact on Biden Environment results of a Joe Biden Environment Pollution Climate change search.
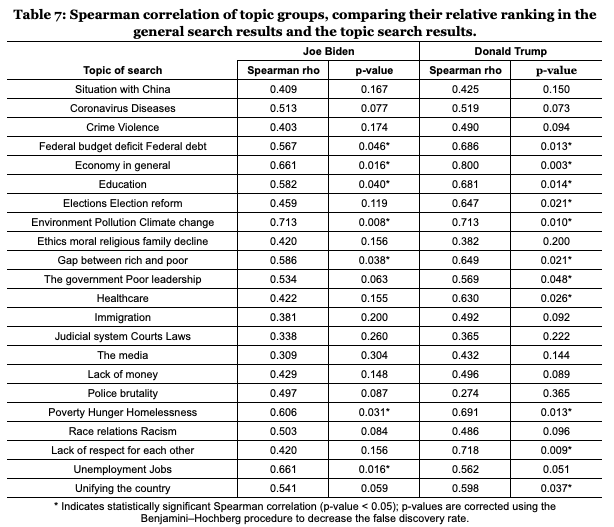
To compute whether these differences are strong enough to alter the relative order of prevalence of topics, we again calculate the Spearman correlation to compare the ranking of the prevalence of these topics in the datasets. The results are reported in Table 7. A high Spearman correlation would indicate a similarity in the relative topic distributions between the general and topic-adapted searches. A high Spearman correlation would mean that the user input, even if it impacts the distribution of topics by altering their frequency of appearances in search results, would not have much influence on the relative prevalence of topics. A low correlation, on the other hand, indicates that the relative distribution of results over topic groups is more heavily influenced and co-constructed by the user. As we see from Table 7, the modifiers of topics make the correlations between the topic rankings for general searches and topic-specific searches decrease substantially in some cases, to the point that, in some topics (15 for Biden and 11 for Trump) p-values demonstrate that there is no statistical significance in the correlations of rankings between general searches and topic searches. But for the other topics (seven for Biden, 11 for Trump), the rankings were still significantly similar. Thus, the relative distribution of topics appeared to be more sensitive to topic searches in the case of Biden than for Trump.
Discussion
This study has investigated the agenda of topics and issues that are curated by the Google search engines, by asking two questions: First, to what extent does the distribution of topics selected by search media replicate the agenda of the news media?; and second, to what extent does searcher input alter this distribution? Through the analysis of topics that emerge in search results in the 2020 United States presidential election, this research makes contributions related to its empirical findings and the connection to agenda-setting theory.
The empirical findings indicate that there is a difference between search media and news media when it comes to the frequency in which the topics are curated, according to the chi-square test on general searches of candidate names compared to the news media baseline. Meanwhile, the ranking of topics—that is, the order of importance in terms of topic prevalence given by search media and news media—is substantially similar, according to the results of Spearman tests on the same datasets. This distinction between proportion of attention and relative attention given to different topics is an important nuance when it comes to agenda-setting in this domain, since it implies that although news media may not have the same power to set the absolute attention that certain topics get, they still largely influence the relative shape of attention given to different topics.
Our findings also speak to the extent to which the search agenda is co-constructed with the user who conducts searches (see Figure 1). For instance, we find that the impact of the use of topic modifiers in queries is not consistent across topics—many (but not all) are boosted as expected but to widely varying degrees. Additionally, most topics searched in addition to the candidate’s name increase the proportion of content that mentioned the topic of Economy, whether that search modifier was directly related with the economy (e.g., Donald Trump Gap between rich and poor and Donald Trump Federal budget deficit Federal debt), but also with terms that are not necessarily in the same topic group (e.g., Donald Trump Environment Pollution Climate change and Donald Trump Immigration). Users clearly have influence on the agenda they are shown, but this is moderated by the search engine in uneven ways. We see a real, but limited power by the user to reshape the order of topics that are represented in the search results, which perhaps counters the imagined absolute power of the searcher and their biases in shaping these results.
One possible reason for these findings may relate back to the concept of the third-level of agenda-setting, which examines how news media not only transfers the salience of topics and their attributes, but also the relationships between those topics (Guo & McCombs, 2011). As we have seen, search engines are a place of connection between different agendas from different agents of communication, because they connect the input of the user with the input of the material they curate. The fact that our findings show that some topics “pull” others, such as with the economy, is a sign that candidates and news stories may be making connections about a variety of topics with the economy, perhaps in order to make their messages and coverage resonate more with voters and readers. The news media may therefore attempt to re-establish their agenda by pairing a third-level agenda with a known user-driven agenda (such as through surveys or search trends) such that when users search on their own agenda, the search engine would then still convey the correlated third-level agenda of the news media.
On some topics, the potential user interest is enough to fill in gaps in the general searches. The appearance of the topic Immigration, for instance, is 0% of topics in the general searches for both candidates, which mirrors the small prevalence of coverage of this topic by news media in this election cycle (only 0.2% of stories in our baseline had that topic)7. But when the search query includes that topic, the proportions increase to 5.8% for Biden and 6.8% for Trump. However, the relative impact that topic searches had in their distributions of their own topics is not always straightforward, and on some topics, the impact of query modifiers about them has a reduced effect. This is the case for Environment, which for Biden goes from 8.1% in generic searches to 9.9% in topic searches. Still, the amount of environmental coverage in search results even just for the general queries for candidate names is far greater than the prevalence of the topic in the news baseline, suggesting that even when there is little content available Google can sometimes boost a topic.
This study has found that Google provides more or less attention to some topics than news media, and that happens even if users try to influence the results by mentioning specific topics. What might cause those disparities in results? In its public communications, Google asserts that their search engine is designed towards finding “information that might be relevant to what you are looking for” (Google, n.d.). According to Google, signals for relevance include whether the web page contains the same keywords as the search query and interaction data from previous users. But even when we tested the use of specific search terms to elicit more results around specific topics, not all topics got an outsized boost in representation. This represents a limited power for even the user to shape the results around some topics. It is possible that Google is supply–limited, and surfaces fewer results about some intersections of topics and candidates because there is less media content available. However, we found no significant correlation between the relative increase of topic representation in the results when searching for queries specific for that topic and the distribution of those topics in our baseline dataset.
At the same time, it’s possible that Google does not consider all those sources in the baseline news dataset equally valuable and might extract potential results from only a limited subset of those sources. For instance, in an environment of polarized news media, metrics of page quality might correlate with a particular perspective (e.g., low quality pages may correlate with some perspectives but not others). We also know from previous work that Google tends to prefer mainstream sources in their curation (Trielli & Diakopoulos, 2019; Trielli & Diakopoulos, 2020). Further work should investigate how factors such as source quality and size may relate to the inclusion of various topical or ideological perspectives which impact the overall search agenda. Stepping back, for journalists, these results also suggest an opportunity to direct coverage: Some topics seem to be under-covered by the media but might be a larger part of the search agenda and may therefore receive outsized attention via search if produced.
Finally, the methodological approach of this work—combining algorithmic auditing with computational content analysis—exposes further opportunities for studying search media. By looking into the content of search results by way of the topics that emerge from them while varying endogenous factors of search (Ørmen, 2016)—in this case, search terms—through a long period of data collection which controls for exogenous factors such as experimentation and randomization of results by the algorithm (Ørmen, 2016), we are able to provide novel insights into how search media relates to the news media and to the extent of the impact that the user has in shaping those results. Future research that investigates the representation, diversity, quality or any other feature of search results should take into account the particular complexities of the content of search results, and not only the sources (i.e., websites), as has been more common for search media audits (Kulshrestha et al., 2019; Trielli & Diakopoulos, 2019). A similar methodological approach as taken here, leveraging targeted queries and media baselines could, for instance, tackle questions of how search media frames various issues such as climate change, immigration, or other topics of societal interest.
Conclusion
In this study, we have conducted an algorithm audit of Google to investigate how the search engine shapes the topics and issues associated with the 2020 United States presidential election. Using datasets of news media articles as baselines, we compared the topics that emerged in general searches about the candidates in the same timeframe and found that while the relative rankings of prevalence of the topics are correlated, there is some divergence in the overall weights in their distributions. For instance, there are salient differences when it comes to the topics of Race or Environment (underrepresented in the news media as opposed to the candidate search results) and Health (overrepresented in the news media as opposed to the candidate search results). We also tested whether specific interests by the searcher, by way of including modifiers to the queries related to specific topics, can reshape those relative rankings, and we found a limited power by the user to reshape the topics in the search results. These findings elaborate an understanding of how search media can drive, shape, or counteract choices made by news and the users. While previous research has focused on biases of Google search, this work contributes to the literature by testing whether Google-curated media is resistant to inputs by news media and users. Additionally, it advances ways of using the framework of agenda-setting theory in the analysis of search media, combining scraping of search results and computational extraction of themes from their contents.
Endnotes
- https://news.gallup.com/poll/1675/most-important-problem.aspx
- Both these datasets were developed by Media Cloud based on reports and definitions provided by Pew Research https://sources.mediacloud.org/#/collections/186572435 https://sources.mediacloud.org/#/collections/186572515
- We used the Newspaper3k Python library for text extraction: https://newspaper.readthedocs.io/en/latest/
- https://github.com/mediacloud/nyt-news-labeler
- https://catalog.ldc.upenn.edu/LDC2008T19
- https://mediacloud.org/support/theme-list
- Reports have also noted the drastic drop in interest in this issue during the 2020 election: https://www.cnbc.com/2020/10/13/immigration-was-a-dominant-i.html
References
Bandy, J., & Diakopoulos, N. (2020). Auditing news curation systems: A case study examining algorithmic and editorial logic in Apple News. Proceedings of the International AAAI Conference on Web and Social Media, 14(1), 36-47.
Bentley, F., Quehl, K., Wirfs-Brock, J., & Bica, M. (2019). Understanding online news behaviors. CHI 2019: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (pp. 1–11). http://dx.doi.org/10.1145/3290605.3300820
Conway, B., Kenski, K., Wang, D. (2015). The rise of Twitter in the political campaign: Searching for intermedia agenda-setting effects in the presidential primary. Journal of Computer-Mediated Communication 20(4), 363–380. https://dx.doi.org/10.1111/jcc4.12124
Courtois, C., Slechten, L., & Coenen, L. (2018). Challenging Google search filter bubbles in social and political information: Disconforming evidence from a digital methods case study. Telematics and Informatics, 35(7), 2006–2015. https://doi.org/10.1016/j.tele.2018.07.004
Diakopoulos, N. (2019). Automating the news: How algorithms are rewriting the media. Harvard University Press. http://dx.doi.org/10.4159/9780674239302
Diakopoulos, N., Trielli, D., Stark, J., & Mussenden, S. (2018). I vote for–How search informs our choice of candidate. In M. Moore & D. Tambini (Eds.), Digital dominance: The power of Google, Amazon, Facebook, and Apple. Oxford University Press.
Dutton, W. H., & Reisdorf, B. C. (2017). Search and politics: The uses and impacts of search in Britain, France, Germany, Italy, Poland, Spain, and the United States. Quello Center Working Paper (No. 5-1-17).
Edy, J. A., & Meirick, P. C. (2018). The fragmenting public agenda: Capacity, diversity, and volatility in responses to the “Most important problem” question. Public Opinion Quarterly, 82(4), 661-685. http://dx.doi.org/10.1093/poq/nfy043
Epstein, R. (2018). Manipulating minds: The power of search engines to influence votes and opinions. In M. Moore & D. Tambini (Eds.), Digital dominance: The power of Google, Amazon, Facebook, and Apple. Oxford University Press.
Epstein, R., & Robertson, R. E. (2015). The search engine manipulation effect (SEME) and its possible impact on the outcomes of elections. Proceedings of the National Academy of Sciences, 112(33), E4512–E4521.
Fischer, S., Jaidka, K., & Lelkes, Y. (2020). Auditing local news presence on Google News. Nature Human Behaviour, 4(12), 1236–1244.
Fletcher, R., & Nielsen, R. K. (2018). Automated serendipity: The effect of using search engines on news repertoire balance and diversity. Digital Journalism, 6(8), 976–989.
Google. (n.d.). How search algorithms work. Google search. https://www.google.com/search/howsearchworks/algorithms/
Groshek, J., & Groshek, M. C. (2013). Agenda trending: Reciprocity and the predictive capacity of social networking sites in intermedia agenda setting across topics over time. Media and Communication, 1(1), 15–27. http://dx.doi.org/10.17645/mac.v1i1.71
Guo, L., & McCombs, M. (2011, May 26-30). Network agenda setting: A third level of media. International Communication Association.
Haim, M., Graefe, A., & Brosius, H. B. (2018). Burst of the filter bubble? Effects of personalization on the diversity of Google News. Digital journalism, 6(3), 330–343.
Hannak, A., Sapiezynski, P., Molavi Kakhki, A., Krishnamurthy, B., Lazer, D., Mislove, A., & Wilson, C. (2013, May). Measuring personalization of web search. Proceedings of the World Wide Web Conference (WWW), 527–538. http://dx.doi.org/10.1145/2488388.2488435
Helberger, N. (2019). On the democratic role of news recommenders. Digital Journalism 7(8), 1–20.
Hu, D. S., Jiang, S., Robertson, R. E., & Wilson, C. (2019). Auditing the partisanship of Google search snippets. Web Conference 2019: Proceedings of the World Wide Web Conference (WWW 2019), 693–704. http://dx.doi.org/10.1145/3308558.3313654
Kay, M., Matuszek, C., & Munson, S. A. (2015). Unequal representation and gender stereotypes in image search results for occupations. CHI 2015: Proceedings of the 2015 CHI Conference on Human Factors in Computing Systems. http://dx.doi.org/10.1145/2702123.2702520
Kliman-Silver, C., Hannak, A., Lazer, D., Wilson, C., & Mislove, A. (2015). Location, location, location: The impact of geolocation on web search personalization. Proceedings of the 2015 Internet Measurement Conference, 121–127. http://dx.doi.org/10.1145/2815675.2815714
Knobloch-Westerwick, S., Johnson, B. K., & Westerwick, A. (2015). Confirmation bias in online searches: Impacts of selective exposure before an election on political attitude strength and shifts. Journal of Computer-Mediated Communication, 20(2), 171–187. http://dx.doi.org/10.1111/jcc4.12105
Kulshrestha, J., Eslami, M., Messias, J., Zafar, M. B., Ghosh, S., Gummadi, K. P., & Karahalios, K. (2019). Search bias quantification: Investigating political bias in social media and web search. Information Retrieval Journal, 22(1-2), 188–227. http://dx.doi.org/10.1007/s10791-018-9341-2
Le, H., Maragh, R., Ekdale, B., High, A., Havens, T., & Shafiq, Z. (2019, May). Measuring political personalization of Google news search. The World Wide Web Conference (pp. 2957–2963).
McCombs, M. E., & Shaw, D. L. (1972). The agenda-setting function of mass media. Public Opinion Quarterly, 36(2), 176–187. http://dx.doi.org/10.1086/267990
McCombs, M., Llamas, J. P., Lopez-Escobar, E., & Rey, F. (1997). Candidate images in Spanish elections: Second-level agenda-setting effects. Journalism & Mass Communication Quarterly, 74(4), 703–717. http://dx.doi.org/10.1177/107769909707400404
McCombs, M., & Zhu, J. H. (1995). Capacity, diversity, and volatility of the public agenda: Trends from 1954 to 1994. Public Opinion Quarterly, 59(4), 495–525.
Mellon, J. (2014). Internet search data and issue salience: The properties of Google Trends as a measure of issue salience. Journal of Elections, Public Opinion & Parties, 24(1), 45–72. http://dx.doi.org/10.1080/17457289.2013.846346
Metaxa, D., Park, J. S., Landay, J. A., & Hancock, J. (2019). Search media and elections: A longitudinal investigation of political search results. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW), 1–17. http://dx.doi.org/10.1145/3359231
Muddiman, A. (2013). Searching for the next U.S. president: Differences in search engine results for the 2008 U.S. presidential candidates. Journal of Information Technology & Politics, 10(2), 138–157. http://dx.doi.org/10.1080/19331681.2012.707440
Mustafaraj, E., Lurie, E., & Devine, C. (2020) The case for voter-centered audits of search engines during political elections. Proceedings of the 2020 Conference in Fairness, Accountability and Transparency, 559–569 http://dx.doi.org/10.1145/3351095.3372835
Nechushtai, E., & Lewis, S. C. (2019). What kind of news gatekeepers do we want machines to be? Filter bubbles, fragmentation, and the normative dimensions of algorithmic recommendations. Computers in Human Behavior, 90, 298–307.
Neuman, W. R., Guggenheim, L., Jang, S. M., & Bae, S. Y. (2014). The dynamics of public attention: Agenda setting theory meets big data. Journal of Communication, 64, 193–214. https://onlinelibrary.wiley.com/doi/abs/10.1111/jcom.12088
Ørmen, J. (2016). Googling the news: Opportunities and challenges in studying news events through Google Search. Digital Journalism, 4(1), 107–124.
Pan, B., Hembrooke, H., Joachims, T., Lorigo, L., Gay, G., & Granka, L. (2007). In Google we trust: Users’ decisions on rank, position, and relevance. Journal of Computer‐Mediated Communication, 12(3), 801–823. https://doi.org/10.1111/j.1083-6101.2007.00351.x
Puschmann, C. (2019). Beyond the bubble: Assessing the diversity of political search results. Digital Journalism, 7(6), 824–843. https://doi.org/10.1080/21670811.2018.1539626
Roberts, H., Bhargava, R., Valiukas, L., Jen, D., Malik, M. M., Bishop, C., Ndulue, E., Dave, A., Clark, J., Etling, B., Faris, R., Shah, A., Rubinovitz, J., Hope, A., D’Ignazio C., Bermejo, F., Benkler, Y. & Zuckerman, E. (2021). Media cloud: Massive open source collection of global news on the open web. https://arxiv.org/abs/2104.03702
Robertson, R. E., & Wilson, C. (2020, February 19). WebSearcher: Tools for auditing web search. [Conference presentation] Computation + Journalism Symposium.
Rubinovitz, Y. (2017). News matter: Embedding human intuition in machine intelligence through interactive data visualizations [Unpublished master’s thesis]. Massachusetts Institute of Technology.
Scheufele, D., Tewksbury, D. (2006). Framing, agenda setting, and priming: The evolution of three media effects models. Journal of Communication, 57(1), 9–20. http://dx.doi.org/10.1111/j.0021-9916.2007.00326.x
Smyrnaios, N. (2015). Google and the algorithmic infomediation of news. Media Fields Journal, 10(10).
Trevisan, F., Hoskins, A., Oates, S., & Mahlouly, D. (2016). The Google voter: Search engines and elections in the new media ecology. Information, Communication & Society, 21(1), 111–128. http://dx.doi.org/10.1080/1369118X.2016.1261171
Trielli, D., & Diakopoulos, N. (2019). Search as news curator: The role of Google in shaping attention to news information. CHI 2019: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (pp. 1–15). http://dx.doi.org/10.1145/3290605.3300683
Trielli, D., & Diakopoulos, N. (2020). Partisan search behavior and Google results in the 2018 U.S. midterm elections. Information, Communication & Society, 1–17. https://doi.org/10.1080/1369118X.2020.1764605
Valenzuela, S. (2019). Agenda setting and journalism. Oxford Research Encyclopedia of Communication. http://dx.doi.org/10.1093/acrefore/9780190228613.013.777
Vargo, C. J., Guo, L., & Amazeen, M. A. (2018). The agenda-setting power of fake news: A big data analysis of the online media landscape from 2014 to 2016. New Media & Society, 20(5), 2028–2049. https://doi.org/10.1177/1461444817712086
White, R. (2013, July). Beliefs and biases in web search. Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 3–12). http://dx.doi.org/10.1145/2484028.2484053
White, R. W., & Horvitz, E. (2015). Belief dynamics and biases in web search. ACM Transactions on Information Systems (TOIS), 33(4), 1–46. http://dx.doi.org/10.1145/2746229
Whyte, C. E. (2016). Thinking inside the (black) box: Agenda setting, information seeking, and the marketplace of ideas in the 2012 presidential election. New Media & Society, 18(8), 1680–1697. http://dx.doi.org/10.1177/1461444814567985
Wu, H. D., & Guo, L. (2020). Beyond salience transmission: Linking agenda networks between media and voters. Communication Research, 47(7), 1010–1033. https://doi.org/10.1177/0093650217697765
Daniel Trielli is a Ph.D. candidate at Northwestern University. As a member of the Computational Journalism Lab, he studies the impact of algorithms in the production and distribution of news, and how journalists can investigate algorithms. Before going into research, he has worked for a decade in local and national newsrooms in his native Brazil.
Nicholas Diakopoulos is an Associate Professor in Communication Studies and Computer Science (by courtesy) at Northwestern University where he directs the Computational Journalism Lab and is Director of Graduate Studies for the Technology and Social Behavior Ph.D. program. His research focuses on computational journalism, including aspects of automation and algorithms in news production, algorithmic accountability and transparency, and social media in news contexts. He is author of the book, Automating the News: How Algorithms are Rewriting the Media, published by Harvard University Press in 2019.